Linux 网络的知识点是非常多的,不可能一篇文章就可能讲清楚。本文参考了 开发内功修炼 的文章,做了简单叙述,算是一个笔记。
TCP 内存
Linux 内存管理
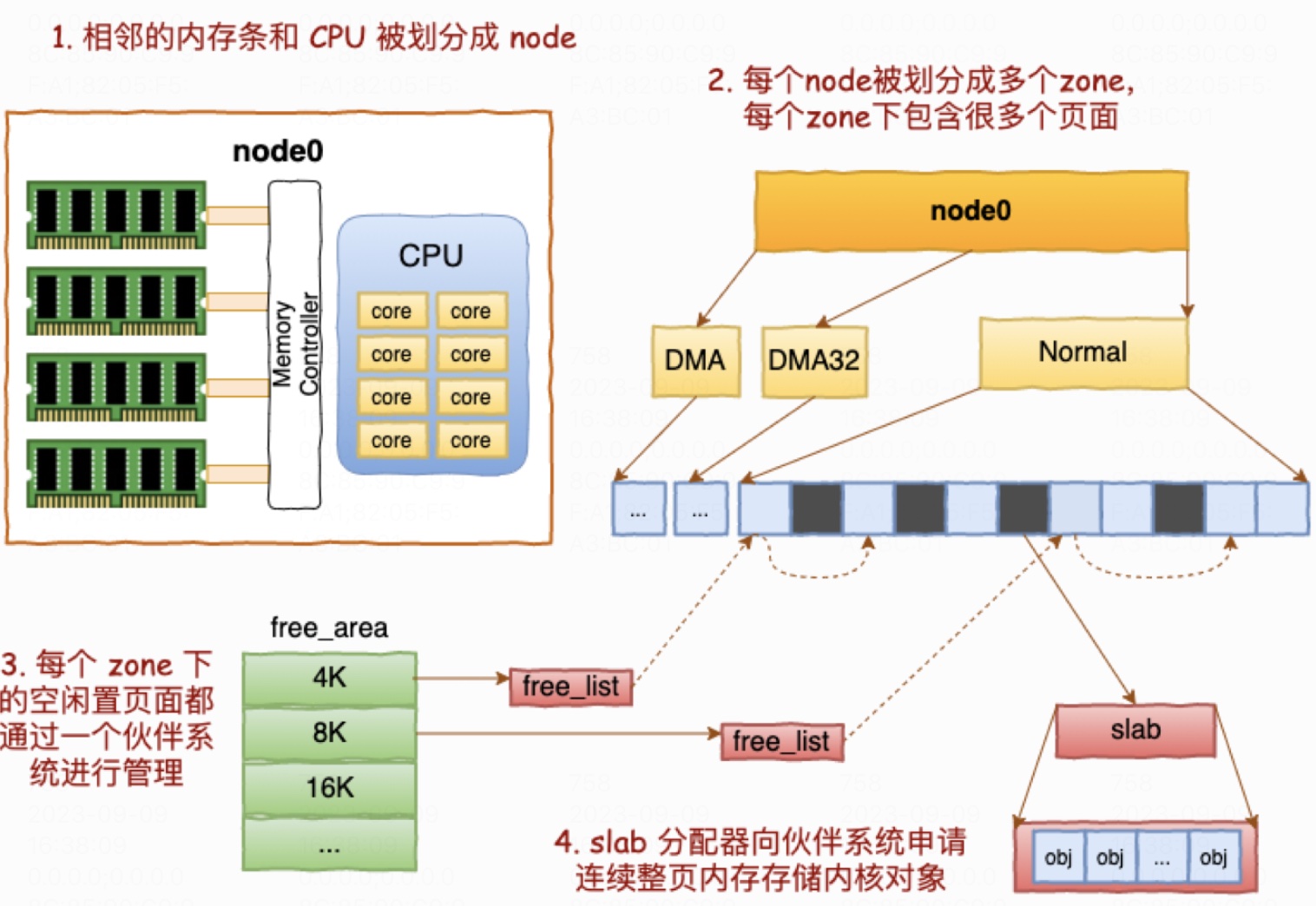
图-1 内存划分
主要记住两个,buddy 和 slab,buddy 用来管理页,slab 用来管理分配的对象。一个 slab 会包含多个 page,它需要从 buddy 中申请。TCP 内核对象就放在 slab 中。
slab 最大的特点就是一个 slab 内只分配特定大小、甚至是特定的对象。这样当一个对象释放内存后,另一个同类对象可以直接使用这块内存。通过这种办法极大地降低了碎片发生的几率。
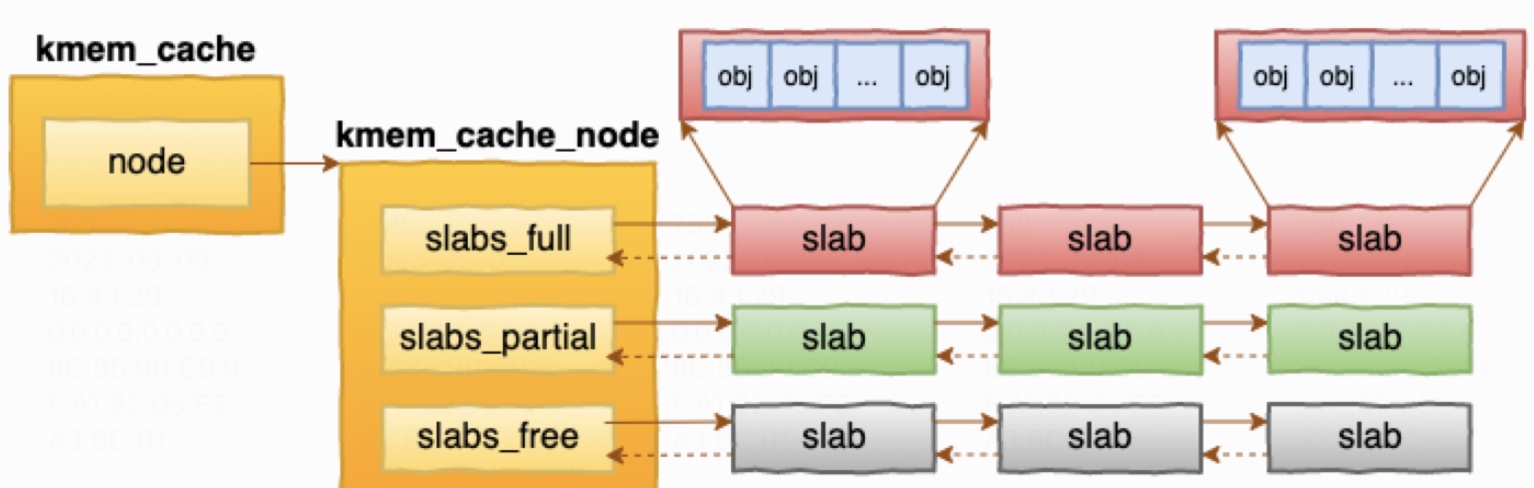
图-2 slab 内存结构
查看 slab 分配情况可以使用命令 slaptop 或者查看文件 /proc/slabinfo。
一台服务器可以支持多少个 TCP 连接
TCP连接四元组是源IP地址、源端口、目的IP地址和目的端口。任意一个元素发生了改变,那么就代表的是一条完全不同的连接了。
作为一个服务器,假设端口固定的是 80,而 IP 也是固定的(不考虑多网卡的情况),剩下的就是目的 IP 和目的端口。理论的最大连接数是2的32次方(ip数)×2的16次方(port数)个连接。这是两百多万亿的一个大数字。这是一个理论数值。
每个 socket 在 Linux 都是作为一个文件而存在的,会受到文件数量限制和内存限制。
文件数量限制包括如下:
- 系统级:当前系统可打开的最大数量,通过fs.file-max参数可修改
- 用户级:指定用户可打开的最大数量,修改/etc/security/limits.conf
- 进程级:单个进程可打开的最大数量,通过fs.nr_open参数可修改
TCP 使用的内存包括内核对象的大小、接收缓冲区、发送缓存区。
接收缓冲区大小如下:1
2
3
4$ sysctl -a | grep rmem
net.ipv4.tcp_rmem = 4096 87380 8388608
net.core.rmem_default = 212992
net.core.rmem_max = 8388608
其中在 tcp_rmem 中的第一个值是为你们的 TCP 连接所需分配的最少字节数。该值默认是 4K,最大的话 8MB 之多。也就是说你们有数据发送的时候我需要至少为对应的 socket 再分配 4K 内存,甚至可能更大。
TCP分配发送缓存区的大小受参数 net.ipv4.tcp_wmem 配置影响。1
2
3
4$ sysctl -a | grep wmem
net.ipv4.tcp_wmem = 4096 65536 8388608
net.core.wmem_default = 212992
net.core.wmem_max = 8388608
在 net.ipv4.tcp_wmem 中的第一个值是发送缓存区的最小值,默认也是 4K。当然了如果数据很大的话,该缓存区实际分配的也会比默认值大。
经过作者测试,在不发送数据的情况下,4G 内存可以建立 100w 个连接。这部分内存基本被 TCP 内核对象占用。如果还包括发送和接收数据的话,可建立的连接数就会继续降低。
TCP 连接的时间开销
正常连接
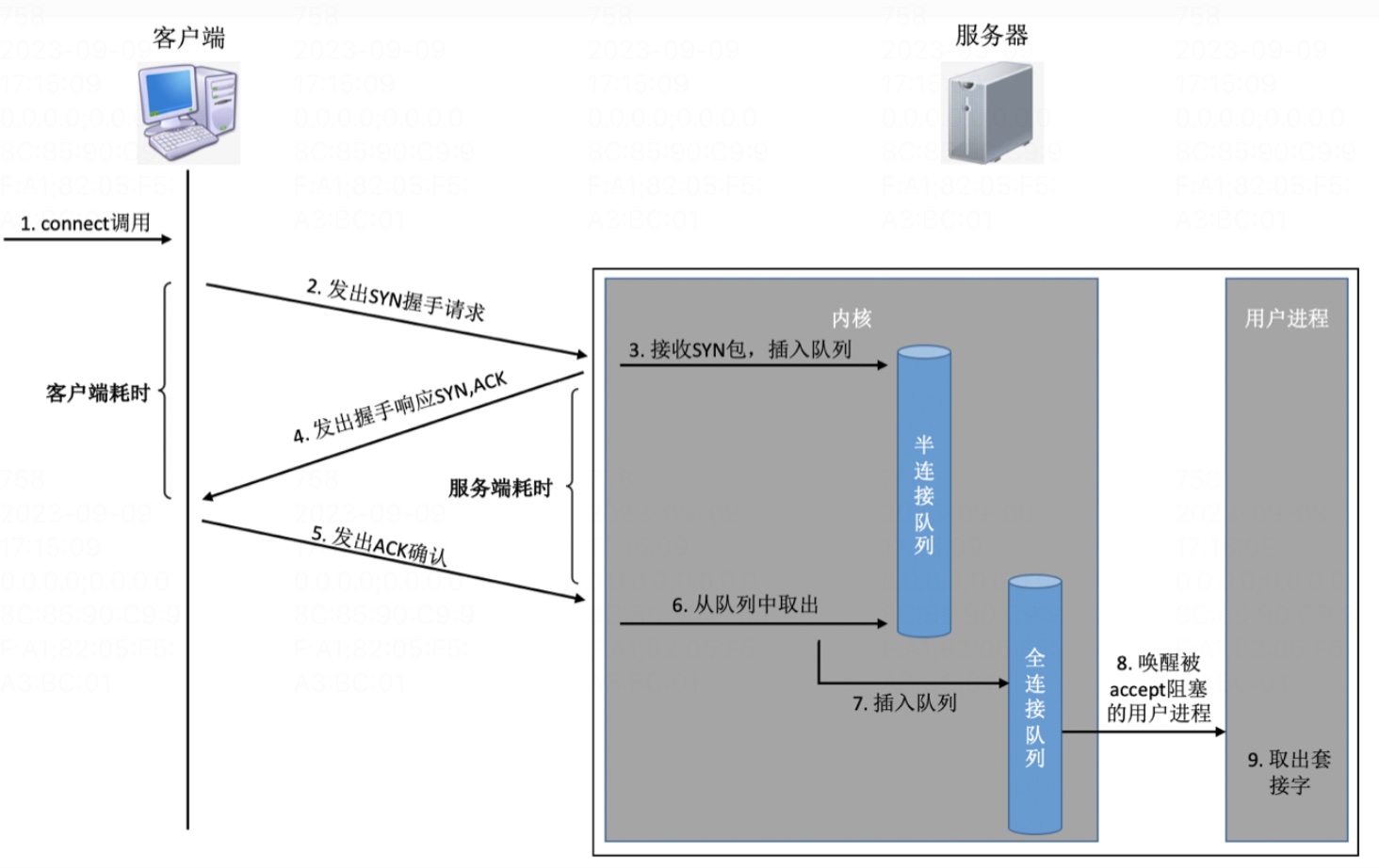
图-3 TCP 建立连接
TCP 建立连接需要三次握手,每一次都有网络延迟。
TCP 连接建立时的异常情况
客户端connect系统调用耗时失控
正常一个系统调用的耗时也就是几个 us(微秒)左右。当 TCP 客户端 TIME_WAIT 有30000左右,导致可用端口不是特别充足的时候, connect 系统调用的 CPU 开销直接上涨了 100 多倍, 每次耗时达到了 2500us(微秒),达到了毫秒级别。当遇到这种问题的时候,虽然 TCP 连接建立耗时只增加了 2ms 左右,整体 TCP 连接耗时看起来还可接受。但是这里的问题在于这 2ms 多都是在消耗CPU的周期,所以问题不小。
解决起来也非常简单,办法很多:修改内核参数 net.ipv4.ip_local_port_range 多预留一些端口号、改用⻓连接都可以。
半/全连接队列满
如果连接建立的过程中,任意一个队列满了,那么客户端发送过来的 syn 或者 ack 就会被丢弃。客户端等待很⻓一段时间无果后,然后会发出 TCP Retransmission 重传。
netstat -s 可查看到当前系统半连接队列满导致的丢包统计,但该数字记录的是总丢包数。你需要再借助 watch 命令动态监控。
1 | $ watch 'netstat -s | grep LISTEN' |
全连接队列丢包统计如下。
1 | $ watch 'netstat -s | grep overflowed' |
如果你的服务因为队列满产生丢包,其中一个做法就是加大半/全连接队列的⻓度。 半连接队列⻓度 Linux 内核中,主要受 tcp_max_syn_backlog 影响 加大它到一个合适的值就可以。
1 | cat /proc/sys/net/ipv4/tcp_max_syn_backlog |
全连接队列⻓度是应用程序调用 listen 时传入的 backlog 以及内核参数 net.core.somaxconn 二者之中较小的那个。
1 | cat /proc/sys/net/core/somaxconn |
改完之后我们可以通过ss命令输出的 Send-Q 确认最终生效⻓度,如下所示。
1 | $ ss -nlt |
Recv-Q 告诉了我们当前该进程的全连接队列使用⻓度情况。如果 Recv-Q 已经逼近了 Send-Q ,那么可能不需要等到丢包也应该准备加大你的全连接队列了。
如果加大队列后仍然有非常偶发的队列溢出的话,我们可以暂且容忍。如果仍然有较⻓时间处理不过来怎么办?另外一个做法就是直接报错,不要让客户端超时等待。例如将 Redis、Mysql 等后端接口的内核参数 tcp_abort_on_overflow 为 1。如果队列满了,直接发 reset 给 client。告诉后端进程/线程不要痴情地傻等。这时候 client 会收到错误“connection reset by peer”。牺牲一个用户的访问请求,要比把整个站都搞崩了还是要强的。
LINUX 网络性能优化建议
耗时优化建议
- 建议1:尽量减少不必要的网络 IO
- 建议2:内网调用不要用外网域名
- 建议3:调用者与被调用机器尽可能部署的近一些
- 建议4: 如果请求频繁,请弃用短连接改用⻓连接
- 建议5:如果可能尽量合并网络请求
- 建议6:注意你的半连接、全连接队列的⻓度
内存优化建议
- 建议1:设置合适的收发缓存区大小
- 建议2:使用 mmap 减少拷⻉
- 建议3: sendfile
CPU 优化建议
- 建议1:监控 ringbuffer与调优
- 建议2:硬中断监控与调优
- 建议3:硬中断合并
- 建议4:软中断 budget 调整
- 建议5:软中断 Gro 合并
- 建议6:减少拷⻉
- 建议7:减少进程上下文切换
- 建议8:配置充足的端口范围