本文是阅读 Milvus: A Purpose-Built Vector Data Management System 论文的总结。
介绍
随着数据科学和 AI 的快速发展,深度学习模型需要将大量的非结构化数据转换为向量,用来做数据分析,比如产品推荐。现存的向量数据库在性能和功能性方面都已经不太符合当前深度学习大规模应用场景的需求。
为了解决向量检索的问题,出现了很多解决方案,比如用关系数据库来存储向量(即有一个列专门存储向量),但是它未对向量计算做特殊优化,检索效率比较低。后来逐渐出现了很多向量数据库,比如 chroma,faiss 等,但是他们也存在两个问题,第一个问题是不能横向扩展,因为他们的设计就是将向量全部存储在主内存中,无法存储在磁盘以及横向扩展到其他节点,第二个问题是检索能力有限,比如缺少按照属性过滤或者多向量同时检索。
此时 Milvus 出现了。
Milvus 具有如下特性:
- 基于 Facebook 开源的 Faiss 向量数据库,支持多种相似度检索算法,包括点积、余弦相似度、欧氏距离等;
- 基于 LSM(Log-Structured Merge Tree),支持内存和磁盘存储,同时也增强了数据写入性能(这是相对的来说的,因为 LSM 涉及磁盘操作,肯定没有直接操作内存块。由于 Milvus 提供了存储容量,突破内存限制,在涉及磁盘操作的情况下,LSM 可以增强磁盘写入性能);
- 充分利用异构多核 CPU 和 GPU 的高效计算能力加速计算,支持 SIMD 向量计算;
- 支持根据属性过滤,比如在产品推荐中,可以根据一个图片向量来搜索价格小于 100 的商品;
- 可以横向扩展,支持多节点存储;
- 支持索引,包括基于量化的索引和基于图形的索引;
系统设计
Milvus 主要由三部分组成,分别是查询引擎、GPU计算引擎和存储引擎,如图-1所示。
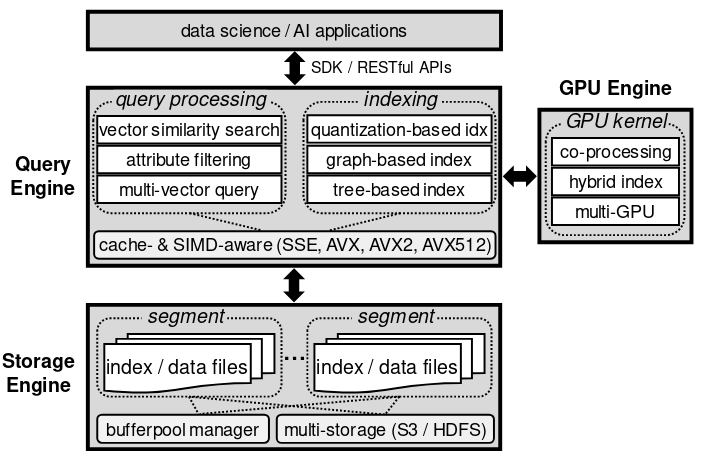
图-1 Milvus 系统架构
查询处理
Milvus 存储的数据都是数值,不管是向量还是属性。它支持三种基本的查询类型,分别是:
- 向量查询:也就是基本的向量相似度查询,它会返回用户相似度最高的前 k 个结果,k 是用户指定的;
- 属性过滤:一个记录可以是由一个向量和多个属性组成的,当查询 k 个结果时可以加上属性过滤,比如要求价格小于 100 元;
- 多向量查询:一个记录可以是由多个向量组成的,当查询 k 个记录时会根据多个向量的聚合函数来过滤结果,如果加权和大于 10;
Milvus 支持以下相似度函数:
- 欧氏距离
- 点积
- 余弦相似度
- 汉明距离
- Jaccard 相似度
Milvus 提供了 Java、C++、Python、Go 等编程语言的 SDK,方便快速接入。
索引
Milvus 支持两种类型的索引,分别是基于量化的索引和基于图形的索引。
- 量化索引:包括 IVF_FLAT,IVF_SQ8,IVF_PQ;
- 图形索引:包括 HNSW 和 RNSG;
Milvus 高级抽象索引接口,以便扩展支持新出现的索引。
动态数据管理
Milvus 使用 LSM-tree 的设计思想来支持高效的新增(insertion)和删除(deletion)操作。新增数据先写入内存的 MemTable 中,当 MemTable 的大小超过设定的阈值后则将 MemTable 设置为不可变,然后将其作为一个块(Segment)写入磁盘。多个小块会合并得到一个大块,直到超过阈值后,块也就不再合并。这种分层合并策略与 LevelDB 非常相似,其实 LevelDB 中的 Level 就是指多级或者分层合并的意思。更新和删除操作也是作为一种特殊的 insertion 来完成的,先将更新或者删除操作写入 MemTable,当落盘写入到 Segment 后,会不断的合并,旧数据就会逐渐被新数据覆盖,从而完成 update 和 deletion 操作。注意,在 LSM-tree 中,deletion 比较特殊,它表示删除一个记录,这个删除标记在多次合并 Segment 中可能会一直存在,用来表示记录已经删除。
Milvus 支持快照隔离级别来保证读和写能共享一致的视图,不会相互干扰。
存储管理
前面提到向量检索 topK 行记录时,每行记录我们称之为实体(entity),相同类型的多个实体就组成了实体表(Entity Table),每一个实体也称之为行(row)。为了便于向量检索,Milvus 基于列式风格来存储实体表中的记录。
向量存储。对于只有一个向量的实体,Milvus 连续存储实体的向量,每个向量存储的长度都一样。对于一个包含多个向量的实体,Milvus 依然使用一列来存储,但是每种向量归类连续存储。比如有三个实体 A、B、C,每个实体包含两个向量 v1 和 v2,那么所有实体的 v1 向量存储在一起,所有实体的 v2 向量存储在一起,所以存储格式是 {A.v1, B.v1, C.v1, A.v2, B.v2, C.v2}。
属性存储。Milvus 将属性一列一列的存储,每一个属性列都是一个 <key, value> 对的数组,key 是属性的值,value 是行 ID。此外,在索引管理下的数据页,Milvus 创建跳跃指针(比如存储最大最小值)来加速范围查询和单行查询。
Bufferpool。类似 MySQL 的 buffer pool,常用的 Segment 会存储在内存中,当内存空间不足时通过 LRU 算法将不常用的 Segment 移除。
多存储。Milvus 不仅可以将数据存储在本地磁盘,还可以将数据存储在 S3、HDFS。这个特性让 Milvus 非常方便的部署在云平台。
分布式。Milvus 采用了现代分布式系统和云平台设计经验,实现了存储计算分离,共享存储,读写分离,一写多读。
异构计算
通过基于量化的索引来介绍 Milvus 的优化,因为它消耗更少的内存并且可以更快的创建索引来加速查询。
背景
首先介绍一下向量量化和基于量化的索引。向量量化的主要思想是应用量化器 z 将向量 v 映射到从码本 C 中选择的码字 z(v)。 K-means 聚类算法通常用于构造码本 C,其中每个码字是中心,z(v) 是最接近 v 的中心。图-2是由10个向量组成的 3 个集群,所以 z(v0), z(v1), z(v2), z(v3) 属于集群 c0。
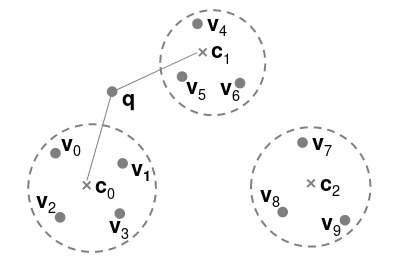
图-2 一个量化的例子
基于量化的索引(比如 IVF_FLAT, IVF_SQ8, and IVF_PQ)使用两类量化器:粗粒度量化器和细粒度量化器。粗粒度量化器使用 K-means 聚类算法将向量划分称 k 个桶(bucket),而细粒度量化器编码每个桶中的向量。不同索引使用不同的细粒度量化器,比如 IVF_FLAT 使用最原始的向量表示方式,IVF_SQ8 是一种压缩向量表示法,它采用一维量化器将 4 字节的向量压缩成 1 字节。IVF_PQ 则使用点积量化将每个向量切分为多个子向量,然后在子空间中使用 K-means 算法。
向量检索包括两个步骤(假设查询 q):
- 根据 q 和每个桶的中心的距离,找到 nprobe 个最接近的桶,比如图-2中最接近 q 的两个桶是 c0 和 c1。参数 nprobe 控制精确度和性能,精确度和性能是一个矛盾体,追求高精确度肯定会降低性能。当 nprobe 的值越高时则精确度就越高,所以性能就比较差了。
- 使用不同的细粒度量化器在最接近的桶中检索向量,比如图-2中的索引是 IVF_FLAT 时,它会从两个桶中检索 v0-v6。
面向 CPU 的优化
CPU 缓存友好优化
基于量化的索引最基本的问题时给定 m 个查询 {q1, q2, …, qm} 和 n 个数据向量 {v1, v2,…,vn},如何快速的找到每个查询 qi 的 top-k 相似向量呢?
Milvus 基于 Faiss 来实现的向量检索,Faiss 使用 OpenMP 来实现多核并行处理,每个线程分配一个查询任务。不过 Faiss 原本的实现存在两个性能问题:
- 它会造成比较多的 CPU 缓存失效(cache missing),因为每次查询时,所有的数据都会流过 CPU 缓存但是却不能被下个查询使用;
- 当 m 很小时,它不能很好的利用多核并行度;
Milvus 的优化。Milvus 使用两个方法来解决上面提到的问题:
- 尽可能重用已经访问过的数据,减少 CPU 缓存失效的问题。Milvus 会经历提高 L3 缓存命中率。
- 细粒度的并行度,它给线程分配数据而不是查询向量,这可以很好的利用多核并行度,关键的一点是数据大小 n 通常远大于查询向量大小 m。
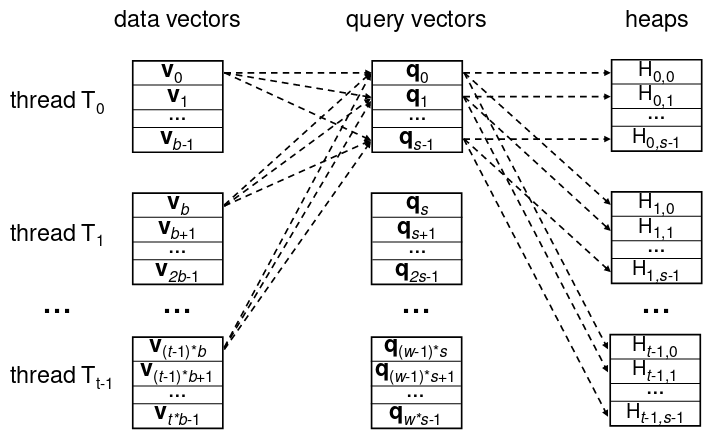
图-3 Milvus 缓存友好设计
图-3中,t 是线程的数量,每个线程 Ti 被分配了 b = n/t 个向量,即 {v(i - 1)*b, v(i - 1)*b + 1, …, , vi*b - 1}。Milvus 然后将 m 个查询分成大小为 s 的多个查询块(query block),每个块都可以放进 L3 缓存中(还包括它的堆)。这里我们假设 m 可以被 s 整除。Milvus 使用多个线程在同一时间计算多个查询块(query block)的 top-k 结果,每当每个线程将它分配的向量加载到 L3 缓存中时,他们会在缓存中比较 s 个大小的查询块(也就是一个查询块有 s 个查询)。为了最小化数据同步的开销,Milvus 为每个查询每个线程分配一个堆,假设第 i 个查询块 {q(i - 1)*s, q(i - 1)*s + 1, …, qi*s - 1} 正在缓存中,Milvus 在第 r 个线程 Tr - 1 上为第 j 个查询 q( i-1 ) * s + j - 1 指定堆 Hr - 1,j - 1。所以,查询 qi 的结果分散在 t 个线程的堆中,这就需要将堆中的结果合并起来得到最终的 top-k 结果。
接着我们来讨论查询块的大小 s 是如何计算出来的,如图-4所示的公式,milvus 会让 s 个查询和它相关的堆能放进 L3 缓存中。
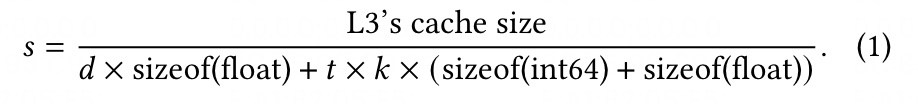
图-4 查询块 s 计算公式
图-4中,d 表示维度,d * sizeof(float) 表示每个查询的大小,因为每个堆的小格子(堆被分成多个大小相等的格子,可以将其看作是数组),每个格子都包括一堆向量 ID 和相似度,所以每个查询的堆大小就是 t × k × (sizeof(int64) + sizeof(float))。
SIMD 友好优化
Faiss 原本已经支持 SIMD 友好的向量相似度查询算法,Milvus 在此基础上做了增强,包括
- 支持 AVX512
- 自动选择 SIMD 指令
Milvus 支持多种不同 SIMD 指令的 CPU ,比如 SIMD SSE, AVX, AVX2, and AVX512,最大的挑战是如何在一个二进制程序里自动选择合适的 SIMD 指令。对于 Faiss 来说,它是靠人工手动编译时指定使用哪种 SIMD 指令,比如加参数 -msse4 来编译。而 Milvus 通过重构 Faiss 代码,将不同 SIMD 指令的代码放在不同的源文件中分别编译,然后根据 CPU 型号并通过 hook 机制链接正确的 SIMD 函数。
面向 GPU 的优化
在 GPU 内核中支持更大的 top-k。Faiss 支持的 top-k 中的 k 最大是 1024,这是因为受到共享内存的限制。Milvus 支持的 k 可以达到 16384,做法是使用多轮累积计算,也就是每轮都找到 1024 个记录,然后再做结果合并。具体流程是,第一轮与 Faiss 一致,先找到 1024 个记录,在之后的每一轮中都先记下最后一轮的距离 dl,显然,dl 是目前距离最大的值,每次都会从找到 1024 条记录中再次过滤掉小于或者等于 dl 的数据,然后再与之前的数据做合并。使用这种方式,Milvus 可以确保之前查到的向量不会出现在本轮中。
支持更多 GPU 设备。Faiss 在编译时就需要指定运行时需要使用的 GPU 个数,Milvus 克服了这个限制,可以在运行时指定。此外,Milvus 使用基于块的调度(segment-based scheduling)来将查询任务分配给一个可用的 GPU 设备,每一个块被一个 GPU 设备服务。这种特性使得 Milvus 非常适合云平台环境,它可以动态的发现新增或者减少的 GPU 资源,然后为查询分配任务。
CPU 和 GPU 的协作设计
GPU 的内存不会很大,不足以放置一定数量的向量。Faiss 通过压缩索引 IVF_SQ8 来减轻内存不足的问题,它会按需将数据从 CPU 主内存中移动到 GPU 内存中。但是这种方法存在两个问题:
- 移动数据所使用的 PCI 带宽利用率并不高;
- 在需要移动数据到 GPU 的情况下,并不总是会带来收益;
充分利用 PCI 带宽。Faiss 不能重复利用 PCI 带宽的原因是,它将向量数据分桶后,一个桶一个桶的复制到 GPU,每个桶的数据量比较小。为了提高 PCI 利用率,很朴素的想法就是使用并行,同时将多个桶的数据复制到 GPU 中。多桶复制在数据删除过程存在缺陷,Faiss 使用了简单的 in-place 更新方法因为每个桶都是单独复制的。幸运的是删除操作在 Milvus 很容易被处理,因为 Milvus 使用了基于 LSM 的 out-of-place 的方法来处理删除或者更新。

图-5 SQ8H 算法
GPU 和 CPU 协作计算。SQ8H 是在 SQ8 衍生出来的,其中的 H 表示 hybird,表示混合计算的意思。Milvus 团队发现,由于昂贵的数据移动,只有当查询批大小足够大时,GPU 才会优于 CPU,这是因为查询批次越多,密集型计算负载就越高。图-5所示,只有查询批次大于一个阈值后,计算才放在 GPU 中进行,并且在 GPU 内存不足时加载必须的桶。否则就采用混合模式,即一部分在 GPU 中计算,另一部分在 CPU 中计算。由于在基于量化索引中的向量检索涉及两部分操作,粗粒度的 K-means 聚类算法和细粒度的的检索。聚类算法由于需要使用大量的数据计算,并且 k 个中心点也比较容易放在 GPU 内存中,所以它很适合放在 GPU 中计算。相反,细粒度检索就比较分散,因为每个查询都不必访问相同的桶。
高级查询处理
属性过滤
一般地,一个带有属性过滤的向量检索会包括两个限制条件:Ca 和 Cv。Ca指定属性的约束条件,Cv指定向量的约束条件。
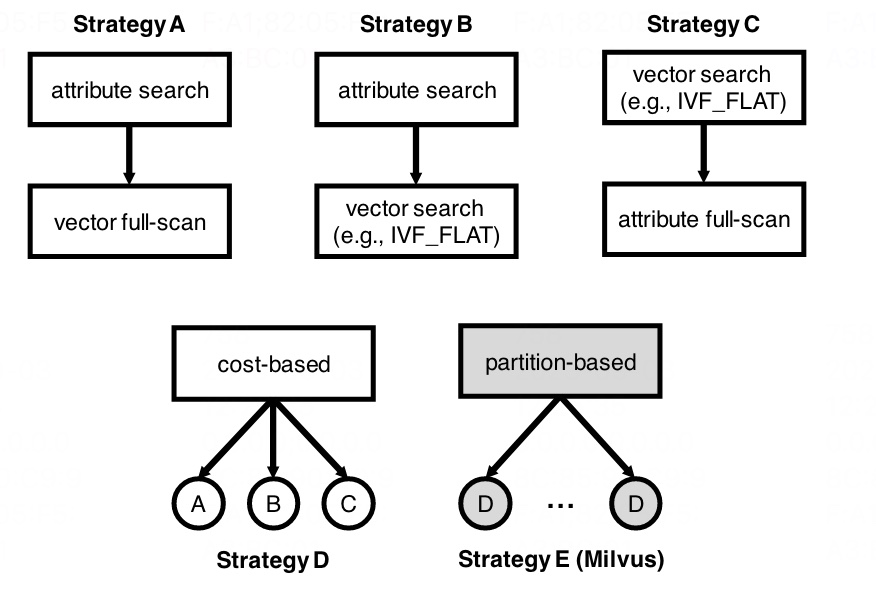
图-6 Milvus 属性查询策略
图-6是 Milvus 实现的几种属性查询策略。
策略A:属性优先的向量完全扫描。首先根据 Ca 过滤条件获取相关的实体,这了可用使用索引做二分查找提高效率,涉及到块(Segment)查询时可用使用跳跃指针。获得相关实体后,再完全扫描结果集并通过 Cv 比较获得最终的 top-k 结果。这个方法适合 Ca 选择性很高时可用过滤大量的数据从而剩下少量的中间结果集,此时向量比较的开销就会小很多。这个策略还有一个特性是它可用产生精确的结果。
策略B:属性优先的向量搜索。与策略 A 类似,唯一的差别是策略 B 使用位图来存储中间结果,位图所表示的信息是向量 iD,当执行向量检索时会与位图做比较,只有满足 Cv 约束条件同时还在位图中的向量才能放在最终 top-k 结果上。这个策略适合 Ca 或者 Cv 的选择性稍微低一点的场景。
策略C:向量优先属性完成扫描。与策略 A 相比,策略 C 首先使用向量检索获得中间结果集,然后再使用属性完全扫描中间结果获得最终的 top-k 结果。这个策略适合 Cv 具有很高的选择性的场景。
策略D:基于代价。基于代价的方法从 A、B、C 中选择一个最好的策略来执行搜索。适用所有场景。
策略E:基于分区。Milvus 提出的一个方法。它记录经常查询的属性,根据属性将数据集划分为多个分区,每个分区的查询策略可用策略 D。具体的是 Milvus 为经常查询的数据建立一个 hash 表,每次查询引用了这个属性都会计数一次。对于一个给定的属性过滤查询,它只需要查询这个分区下的数据(该分区的数据范围符合查询条件),此时就只需要做向量过滤了,因为属性条件已经完全符合查询条件了。
举个例子,假设很多查询都涉及价格属性的过滤,Milvus 会根据价格将数据集拆分成 5 份,分别是 P0[1-100],P1[101-200],P2[201-300],P3[301-400],P4[401-500],当属性查询约束条件 Ca 是 [50-250] 时,只有 P0、P1、p2 三个分区符合条件,因为他们覆盖了 [50-250] 的数据集。接着 Milvus 就只在这 3 个数据集中使用 Cv 进一步过滤数据得到最终的 top-k 结果。
当前的版本中,Milvus 基于历史数据以离线的方式创建分区以服务在线的查询需求。分区大小可以由用户指定,选择一个合适的分区大小也非常重要。如果分区数量太小,意味着每个分区的向量数据就非常大,这不利于通过剪枝(prune)的方式剔除不相关分区。如果分区数量太大,意味着每个分区的向量数据就非常小,这会让向量索引退化成线性搜索。以 Milvus 的经验来看,一般一个分区包含 100 万个向量是最佳的,比如 10 亿规模的数据集需要 1000 个分区。
多向量查询
有些场景会需要使用多个向量来标识一个实体用在向量检索中,每个实体都包含 u 个向量:v0、v1、…、vu-1。一个多向量查询就是对每个向量 vi 的相似度函数 f (比如点积)执行聚合计算 g 而得出的 top-k 个结果集。比如说 X 和 Y 两个实体的相似度的向量计算就是 g(f(X.v0, Y.v0), …, f(X.vu-1, Y.vu-1))。聚合函数 g 一般是一个单调函数,比如加权求和、最大最小值、平均数、中位数等。
朴素解决方案。每个查询都发起一个 top-k 查询得到中间结果集,最后再对中间结果集在做进一步的计算得到最终的结果集。这种方法的准确率并不高。与分表模式下分页查询的效果非常类似,比如查询 10 条记录时,先去每个表获取 10 条记录,然后再对他们做排序得到最终的 10 条记录。
向量融合。要讲述向量融合(vector fusion),我们先假设向量相似度函数是点积。设 e 是结果集中的任意实体(可以理解为行),每个实体都包含 u 个向量 v0,v1,…,vu-1。这个方法存储每个实体 e 的 u 个向量为拼接向量 v,即 v= [e.v0, e.v1, …, e.vu-1]。q 是一个查询实体,查询期间,该方法会在 q 实体的 u 个向量中应用聚合函数 g,产生一个聚合查询向量。比如一个加权和的聚合函数,wi 表上每个向量的权重,那么聚合查询向量就是 [w0 * q.v0, w1 * q.v1, …, wu-1 * q.vu-1]。然后它将聚合查询向量与数据集中的拼接向量比较得到最终的 top-k 结果。这个方法要求相似度函数必须是可以分解的,比如点积。
迭代合并。当不能使用向量融合方法时就可以使用本方法。本方法借鉴了 Optimal Aggregation Algorithms for Middleware 论文中提到的 NRA 算法思想,NRA 是一个通用的 top-k 查询处理方法,Milvus 在此基础上做了两项优化:
- 使用 VectorQuery(q.vi, Di, k‘) 来获取 top-k‘,其中 k‘ 是以自适应的方式设置的;
- 迭代次数增加了上限,因为 Milvus 使用的是近似值;
迭代合并算法如图-7所示。

图-7 迭代合并
系统实现
异步处理
Milvus 通过异步来提供系统吞吐量,包括数据写入和索引的构建。比如用户提交一批数据写入请求后,Milvus 先将写入请求落盘,这类似数据库中的日志,然后回复用户 ack,同时启动一个后端线程来完成数据写入操作。用户通常无法立即看到他们提交的写入请求,为了可以让用户看到,Milvus 提供了一个 flush API,它会阻塞用户请求,直到所有挂起的后端任务都完成。
快照隔离
Milvus 使用 LSM 算法,数据先写入内存中(MemTable),发生溢写时将数据写入到磁盘,即 Segment。每个 Segment 都有多个版本,当 segment 改变时(比如溢写、合并、索引构建)就会产生一个新的版本。任何时候,所有最新的 segment 构成一个快照。每个 segment 可以被一个或者多个快照引用,如果没有快照引用 segment,后端线程在 gc 时会将其回收。
分布式计算
为了可用性和可扩展性,Milvus 是一个支持多节点的数据管理的分布式系统。Milvus 通过共享存储(shared-storage)的方式将存储和计算分离以达到最好的弹性。存储计算分离广泛应用在现代云平台系统中,比如 Snowflake 和 Aurora。
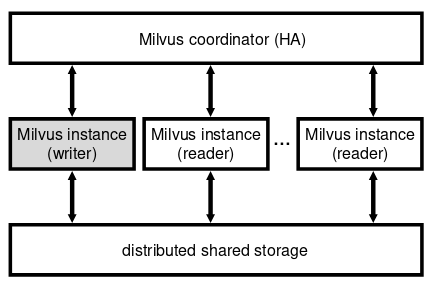
图-8 Milvus 分布式计算
图-8所示是 Milvus 的三层架构,存储层是基于 S3 的存储,因为它是高可用的,计算层处理用户请求,包括数据写入和查询请求。当然它也有本地内存和 SSD 来缓存数据,避免频繁的访问 S3。此外,Milvus 还有一个协调器来维护系统分片和负载均衡等元数据,协调器层使用 3 节点的 zookeeper 来保持高可用。
计算层是无状态的节点,具有弹性。它包括一个 writer 节点实例和多个 reader 节点的实例,writer 节点负责数据更新请求(包括 insertion,deletion 和 update)。多个 reader 节点处理用户的查询请求。reader 中的数据分片基于一致性 hash 算法,分片信息存储在协调器节点。所有的计算层实例都是由 Kubernetes 来维护的,当一个节点 crash 时 k8s 会很快重启服务以替换旧节点。如果 writer 崩溃,Milvus 依赖 WAL(write-ahead log)来保证原子性。因为计算层节点是无状态的,所以他们崩溃并不会造成数据的不一致。
为了减少存储和计算之间的网络负载,Milvus 做了两个优化:
- 计算层仅仅将日志发送到存储层,类似 Aurora;
- 每个计算实例都会一定的内存和 SSD 来缓存数据,以此来减少对共享存储的访问;