简介
Dynamo 是 Amazon 推出的一款基于 KV 读写的 NoSQL 数据库,具有高可用性,可扩展,弱一致性的分布式特性。Dynamo 使用的技术有:
- 一致性哈希算法来实现分区;
- 使用向量时钟来记录数据版本;
- 使用 Gossip 协议交换节点的信息;
架构
Dynamo 的定位是可扩展、写高可用,使用向量时钟记录数据版本实现到写高可用。Dynamo 架构见图1所示。
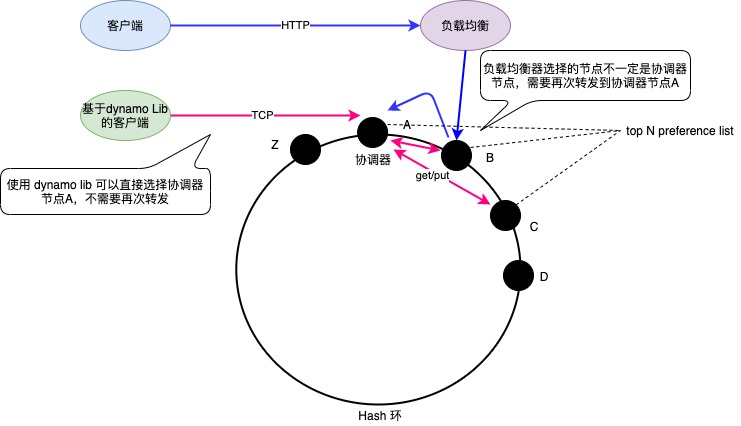
图-1 Dynamo 架构
图-1展示的特点有:
- Dynamo 客户端支持两种模式,走 HTTP 的负载均衡延迟大,使用 Lib 库内部集成路由可以直接连接协调器;
- Dynamo 支持的操作基本只有
get(key)和put(key, context, object); get和put操作都需要连接协调器节点,由协调器向 preference list 的 N - 1 个节点发起请求,只有返回特定数量的成功返回通知客户端请求成功并返回数据;
关于 preference list ,可以看做是一个分区的多副本节点,他们存储的数据都相同。preference list 的第一个节点一般是协调器节点(并非绝对,请参考“读写”一节),它负责接收 get 和 put 操作。对于 put 操作,协调器节点会在本地生成 (node, counter) 这样的向量时钟来记录数据的版本,然后将数据连同版本一起发给 preference list 中的其他节点。
get 和 put 的多副本一致性使用 quorum 协议,如果 preference list 的节点数量是 N,要求的最小 get 成功数的节点数是 R ,最小 put 成功数的节点数是 W ,则 R + W > N。这样才能保证即使在分区场景下写入节点不能完全成功,但是 get 读取时要求 R 个节点正常返回,这 R 个节点总有一个节点包括最小数据。协调器会将数据合并返回给客户端。
一致性哈希
一致性哈希算法是为了解决一个节点加入或者移除集群时尽量少移动一些元素,核心思想是当一个节点加入时需要尽量分担其他节点的元素,当一个节点删除时集群剩余节点需要分担这些元素。一致性哈希算法的原理本文不会叙述,请阅读一致性Hash算法详解。
图-1所示,在一个哈希环上,集群内所有节点都随机的在环上插入一个位置,每个节点都负责存储前部分健空间。比如节点 A 负责存储 C 到 A 这部分空间的所有 key。如果节点 A 移除,C 到 A 这部分空间的 key 全部交给 B 分担,这样就不会动到整个集群 key。想想取模的分片方式,如果节点发生变化,因为“key mod x“会将整个集群的 key 重新计算,移动大量的 key。不过图-1左边的哈希环还存在问题,节点 A 移除后,节点 B 分担的 key 数量太多,比 C 多,导致数据倾斜严重,分布不均。需要采用图-1右侧的哈希环,在上面添加虚拟节点。也就是 A 、B 、C 三个节点都虚拟出多个虚拟节点,放置在哈希环上。此时,当节点 A 移除时,A 负责 key 就可以均匀的分配给 B 和 C,继续保持 key 的均匀分布。
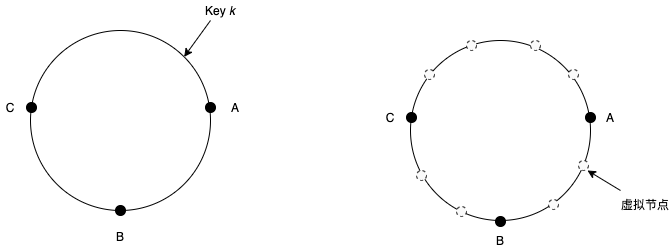
图-2 一致性哈希
使用虚拟节点之后,preference list 要求节点都必须是不同的物理节点。
分区
Dynamo 使用一致性哈希算法处理分区问题,使用虚拟节点解决数据分布不均问题。
Dynamo 支持 3 种分区策略,每种分区策略都有各自的优缺点。在叙述策略前,先说说 token 是什么意思。token 简言之就是环上的位置,节点插入在环上的点,这个点就是 token,而点的位置就是 token 的值。如此一来,tokenn-1 至 tokenn 这个空间就是由 tokenn 这个点的节点负责存储。
图-3是 Dynamo 论文《Dynamo: Amazon’s Highly Available Key-value Store》第6.2节的截图。
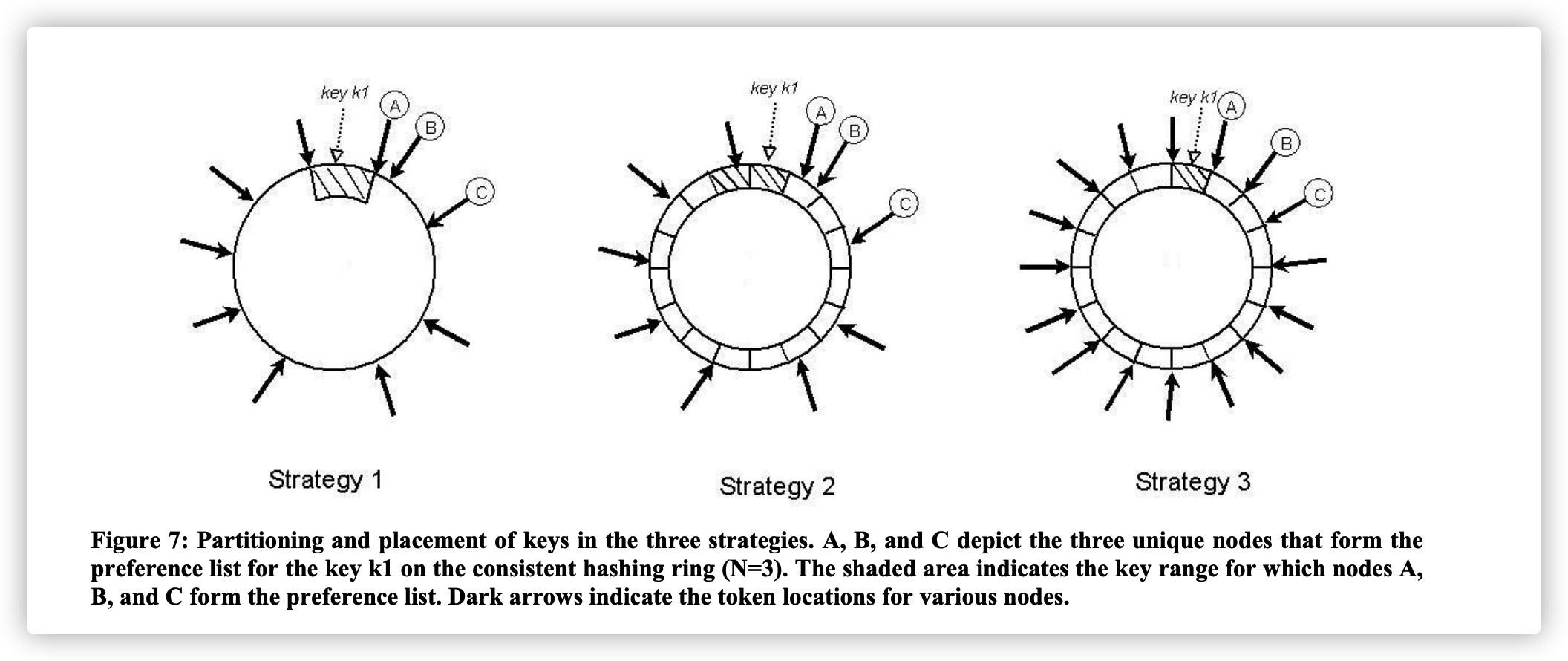
图-3 分区策略
T 个随机 token,根据 token 的值做分区
每个节点都有 T 个 token 随机的插入到哈希环上,由于每个 token 的值不一样,这样就导致每个 tokenn-1 至 tokenn 的区间大小都不同,存在数据倾斜的情况。需要注意,这种分区策略,token 的值用来决定哪个节点分担哪个分区,如同图-2中的第一幅图。
这种分区策略最简单,但也带来一些问题:
- 数据倾斜风险大,刚刚也谈到,因为随机的 token 值造成每个区间大小都不同;
- 新节点加入或者移除时,某个节点的区间需要迁移到新节点时,需要遍历本地存储的 key 空间,重新计算 key 的位置来决定是哪个节点负责该 key。遍历是耗时操作,线上环境一般一个节点会有好几千万或者上亿的 key,需要在开启后端线程去遍历;
- 新节点和旧节点的 Merkle tree 的哈希值需要重新计算。Merkle tree 用来快速检测副本数据是否一致,后面复制一节再谈。因为节点的加入和移除,都会将原来的分区拆分,比如旧分区是 tokenn-1 至 tokenn,新加入节点后,分区拆分成两个,分别是 tokenn-1 至 tokenm-1 和 tokenm 至 tokenn;
- 数据快照归档麻烦,由于每个区分大小不同,而且分区是由 token 来决定,导致分区数据存储时不好存储在同一个文件内,归档时就需要遍历,当然,这也是数据迁移需要遍历的原因。
总的来说,这种分区策略,是因为分区不固定,依赖 token。需要使用一种分区固定的策略,请看下面两种策略。
T 个随机 token,每个分区的大小相等
这是一个过度阶段的分区策略,前面谈到,分区需要固定是很有必要的,所以这里就是将分区固定下来。每个节点都有 T 个 token 随机的插入到哈希环上,且每个分区范围相同。假设分区个数是 Q,则 Q 远大于 N 且 Q 远大于 S * T,其中 N 表示副本数,S 表示集群节点个数。
使用这种分区策略,token 的值已经不能直接用作分区,而是需要间接定位分区。图-2中的第二幅图,先计算 key 在哈希环上的位置,定位出这是哪个分区。然后计算出分区的结束位置,从这里开始,顺时针在哈希环上找到第一个节点,该节点分担这个分区的存储。
这种分区策略的优点是:
- 分区固定,添加和移除节点时,不会将分区拆分,此时可以将同一个分区内的数据全部存储在同一个文件中,数据迁移时不会拆分,Dynamo 内部把这种特性叫做解耦;
Q/S 个 token,每个分区的大小相等
与第二个策略类似。
每个节点的在环中随机的插入 Q/S 个 token,分区大小相同。
这种分区策略的优点是:
- 分区固定;
- 可按照分区文件存储数据,迁移和快照归档时不需要遍历;
- 数据倾斜风险小,每个分区大小都相同;
复制
复制是实现高可用的最基本方法。每一个 key 都会存储在多个节点上,当其中一个节点异常时,其他节点还能继续提供服务。每个 key 都由它的协调器节点负责存储和复制,协调器节点一般就是 key 顺时针找到的第一个节点(非绝对,请参考“读写”一节)。协调器继续从后面的 N - 1 个不同物理节点找到副本节点,将数据复制到这些节点上,这些节点称为 preference list,preference list 构成了一个分区内的多副本节点,第1个节点就是协调器节点,从图-1中看,A、B、C 是一个 preference list ,他们都负责存储 Z-A 之间的数据。
向量时钟
向量时钟理论出现在 Lamport 的 Time, Clocks, and the Ordering of Events in a Distributed System 论文,它说的是在一个分布式系统中,哪些事件能够确定顺序关系,哪些不能。能够确定有顺序关系的就具有因果关系(causality),因先于果。如果分布式系统中有 A 、B 两个节点,如果 A 节点产生了一个事件 e,打上一个标签,将事件传递给 B ,B 节点第一次拿到这个事件后就能确定它,B 节点后续产生的事件 e1、e2 肯定晚于事件 e。
Dynamo 使用的向量时钟格式是 [node, counter] ,node 是协调器节点。当协调器节点收到一个 key 的 put 操作时,它会增加 counter 的值,记录一下 node 为自己,然后将这些数据复制到其他节点。
图4是 Dynamo 论文《Dynamo: Amazon’s Highly Available Key-value Store》第4.4节的截图,它展示的是一个 key 的数据版本从 D1 到 D5 的演变过程,其中涉及合并、替换旧版本数据。
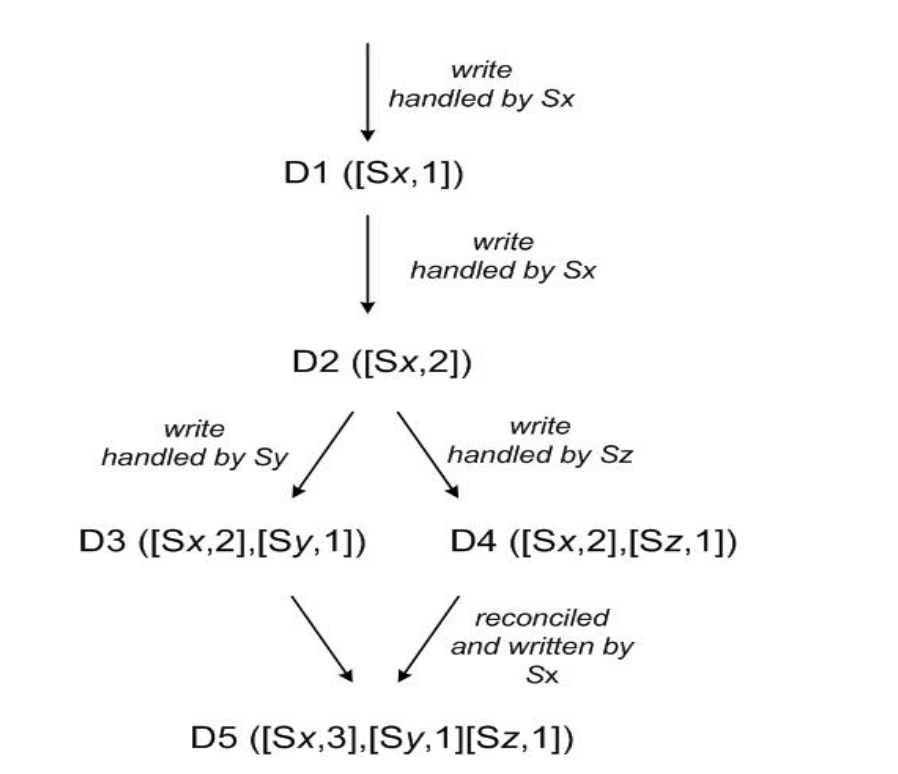
图-4 向量时钟
Sx节点首先收到 key 的 put 操作时,此时的数据版本是D1,使用 ([Sx,1]) 这个时钟向量来记录,Sx 然后将该数据附加版本信息复制给 preference list 的其他节点。接着 Sx 再次收到 put 操作,数据版本是 D2,使用 ([Sx, 2]) 来记录。Sy 收到了 ([Sx,2]) 这个版本的数据,然后 Sy 作为协调器收到 put 操作,数据版本是 D3,使用 ([Sx,2],[Sy,1)]) 来记录。此时 Sy 异常,没有将数据复制出去,Sx 和 Sz 都收不到。类似的,Sz 也收到了 put 操作,使用 ([Sx, 2],[Sz,1]) 来记录版本 D4。此时各节点的数据版本是:
Sx: ([Sx,2])
Sy: ([Sx,2],[Sy,1)])
Sz: ([Sx, 2],[Sz,1])
此时 Sy 和 Sz 存在数据冲突,或者产生了分支。可以这样做个类比,Sx 是一个 git 分支,Sy 首先从 Sx checkout 出来,然后做了修改提交。Sz 也从 Sx checkout 一个分支,做了修改提交。Sy 要合并 Sx 时就会参数冲突,因为这相当于是同时改了代码,需要用户确认如何合并。
当 Sx 、Sy 和 Sz 都恢复时,任何一个节点收到 put 操作时都会产生一个冲突,数据需要合并。
由于处理 put 操作的协调器并不是每次都是向前 N-1 个 preference list 节点发起写数据操作(有些可能可能异常或者发生网络分区),导致数据项的向量时钟数量会增加太多,因此 Dynamo 可以限制保留向量时钟数量的数量,丢弃旧的向量时钟,这种情况发生时理论上是会造成数据丢失的。
读写
Dynamo 的操作主要是:
get(key)put(key, context, object)
key 用来决定哪些副本需要读写数据,context 包含数据项的元信息,比如版本号。context 与 object 保存在一起,因此也可以用来验证 context 对应的 object 是否有效。
图1所示,当执行 get 或者 put 操作时,可以通过:
- HTTP 代理,业务程序没有依赖,但是负载均衡代理时增加了延时;
- 客户端SDK,业务程序需要依赖本SDK,不需要经过代理,可降低延时;
负责处理 get 和 put 操作的节点称为协调器,它继续向其他节点发起读写操作,如果是:
get操作时,协调器需要向高优先级的前 N - 1 个 preference list 的健康节点发起get请求,等到收到 R - 1 个节点回复成功时,再将返回数据返回给客户端,如果数据版本存在分支冲突的情况,需要客户端去解决分支冲突的问题(想象成 git 中的分支冲突处理);put操作时,协调器需要向高优先级的前 N - 1 个 preference list 的健康节点发起put请求,等到 W - 1 个节点回复成功时,再通知客户端写入成功。如果需要更新一个数据时,必须先发起get请求拿到context数据版本,将其传给put方法;
Dynamo 的数据弱一致性使用 quorum 机制,遵循 R+W>N 。
协调器节点一般是 preference list 的第一个节点,但是这并不是绝对的。因为如果一直都是第一个节点来做协调器,负载会出现不均的情况。特别是对于写操作而且,一般就不是选择第一个节点作为协调器节点。由于 put 前一定要先 get,为了平衡写入,Dynamo 会优先选择 get 返回最快的节点作为 put 节点的协调器。
get 和 put 操作并不总是选择前 N 个 preference list 节点,因为有些节点可能发生异常或者网络分区,此时 Dynamo 会跳过这些节点。那么如果节点异常后,数量不足 R 或者 W 个节点时,Dynamo 时如何做到最大努力保证读写的高可用呢?
错误处理
Hinted Handoff
上文说到,Dynamo 使用一种 quorum 机制来保证数据弱一致性,而 Dynamo 的目前是要保证读写的高可用,哪怕集群只有一个节点,读写还是要支持的,这样就会造成支持 R 或者 W 节点的数量不足,不满足 quorum 机制。事实上,Dynamo 使用一种叫做“sloppy quorum“机制,不会严格的使用 quorum 机制,这样就可以支持读写的高可用。
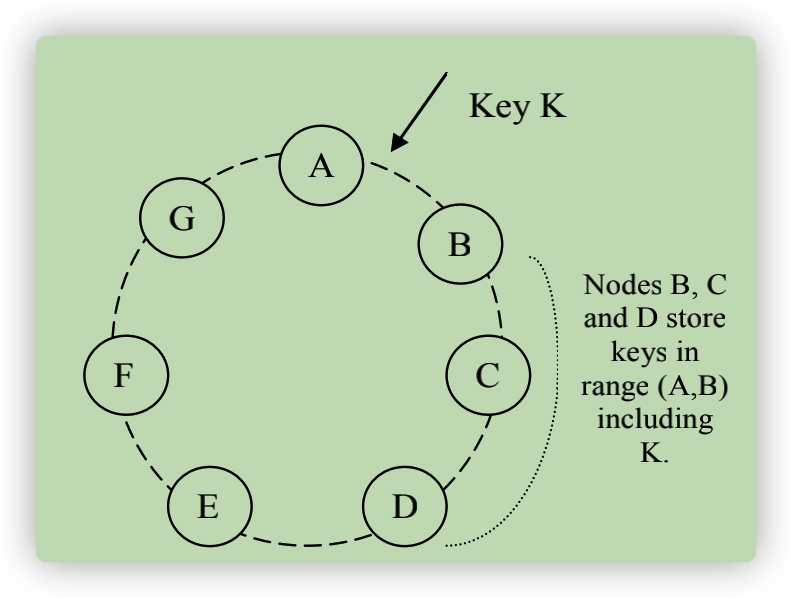
图-5 Key 的分区和复制
根据图5来说明“sloppy quorum”的机制。假设根据 Dynamo 配置,N = 3。当向 A 节点写入数据时,节点 A 异常停止服务,本来应该存在A中的副本,现在会转发到节点 D(假设本例是转发到节点D),而节点 D 知道现在是暂时存储节点 A 的数据,需要在另一个本地数据集中存储节点 A 的数据,并做好标记,然后定期扫描。当节点 A 恢复正常时,节点 D 需要将这部分数据移动到节点 A。这种弱 quorum 机制体现的是并不是总是从 top N 个 preference list 选取节点,比如说之前的 top N 节点列表是 A、B、C,而现在是 B 、C 、D,这样可以提高系统的可用性,但是数据一致性会降低。
“sloppy quorum”机制有个形象的比喻,想象自己回家用钥匙开门的例子,我们首先可以把备用钥匙放在邻居家,自己留一把。当某次回家时发现自己钥匙掉了或者落在公司,这个时候我们可以去邻居家拿备用钥匙去开门。
Hinted handoff 算法对于节点故障频率少、故障时间短很有效,主要是数据量小,维护数据一致性时需要迁移的数量也不多。
副本同步
考虑上节 Hinted handoff 算法中故障节点 A 恢复时,它已经是丢失了部分数据了,它该如何追上丢失的数据呢?
在物理学中,使用熵entropy来表示系统的混乱程度。在计算机世界中,也使用该词来描述数据不一致的情况。所以英文的 Anti-entropy 就表示对抗混乱,使得数据往一致上靠的意思。
Merkle Tree 算法使得 Dynamo 可以检查局部数据不一致并且只需要复制少量数据就可以达到最终一致性,不过这里对于新节点加入的场景不适用。
我们通过一幅图来说明 Merkle Tree 算法的原理。图-6 摘自维基百科 Merkle tree。Dynamo 可以根据分区当作一个数据块,对该数据块做一个哈希算法计算出它的 hash 值,假设该数据块是图-6中虚线框内的 L4,它的哈希值是 1-1。它的父节点包括两个节点,父节点的哈希值也必须是通过子节点的哈希值计算出来的,图-6就是哈希值为 1 的节点。如果往顶部开始搜索,每搜索到到一个节点就检查其哈希值是否与自己节点的 Merlke Tree 做对比,如果不想等,表示这颗子树下的部分数据块的数据与自己不一致,此时就需要继续往下找。如果找到的子树根节点的哈希值与自己的 Merkle Tree 哈希值相等,就可以停止搜索该子树。否则继续搜索,找到不一致的数据块。然后交换数据,取最新的数据保存。

图-6 Merkle Tree 算法模型
根据图5来说明“sloppy quorum”的机制。假设根据 Dynamo 配置,N = 3。当向 A 节点写入数据时,节点 A 异常停止服务,本来应该存在A中的副本,现在会转发到节点 D(假设本例是转发到节点D),而节点 D 知道现在是暂时存储节点 A 的数据,需要在另一个本地数据集中存储节点 A 的数据,并做好标记,然后定期扫描。当节点 A 恢复正常时,节点 D 需要将这部分数据移动到节点 A。这种弱 quorum 机制体现的是并不是总是从 top N 个 preference list 选取节点。
成员和异常检查
新节点加入
Dynamo 集群最开始启动时,需要配置种子节点,这几个种子节点彼此能相互通信交换信息。
管理员通过向集群内任意节点发送一个 join 消息,表示有新节点加入。处理新节点加入的节点维护的成员列表,需要增加一个版本,表示成员列表信息有变化,其他节点与这个节点通信时就会交换成员列表信息,发现成员列表有变化,就立刻更新。这个设计模式跟 Redis Cluster 很像。当然,对于异常情况下,比如节点停机,是不会更新成员列表的,除非管理员通过控制台移除一个节点时,成员列表才会更新。
当新节点加入时,新节点需要自己选择 token (哈希环中的虚拟节点,前文已经说明),这些信息会先保存在新节点本地,当与集群其他节点通信时,会交换节点负责的 token 信息,这样就能达到最终一致性,大家都平衡下来。
所以每个节点都知道其他节点负责哪些分区,如果该节点收到请求发现不是自己负责,则将请求转发正确的节点去。
以图-5为例,说明一下节点加入之后的事情。假如节点X加入在A和B之间,那么节点X需要负责存储(F, G], (G, A] and (A, X] 范围的数据,节点 B、C、D 也会有部分 key 集合不再负责,需要将 key 信息同步给节点 X。
异常检测
Dynamo 使用 Gossip 协议与其他节点通信,如果节点 A 向节点 B 发送消息,比如心跳消息,节点 B 没有回复,节点 A 内部会标记节点 B 不可用,如果转发请求或者 hinted replicas 就不会使用节点 B。
可以想象 Dynamo 内部维护的成员列表,每个成员都维护了一个状态,可以表示 活跃、停机/不可用、已移除。如果状态是已移除,Dynamo 不会与它通信,并且在一定的时间之后,会将该节点移除成员列表。现在不移除的原因是还需要将这个状态信息同步到其他节点,让其他节点知道有一个节点已经被标记为移除。如果节点状态是停机/不可用时,之后该节点需要不停的向不可用节点发起消息,检查它是否活跃。
总结
Dynamo 优秀的设计有:
- 改进哈希一致性算法,虚拟多个节点,使得节点数据尽量平均;
- 向量时钟的数据版本号算法,可以发现数据冲突,事实上,向量时钟算法最先是 Lamport 提出的 Time, Clocks, and theOrdering of Events ina Distributed System 这篇论文;
- Merkle Tree 算法解决数据调谐(reconcile)时移动的数据量,但是节点加入时依然需要移动大量数据;
- 分区算法,这点比较难懂,感觉是向 Redis Cluster 的 slot 算法上靠;
- 去中心化的设计;
事实上,亚马逊内部只是在购物车上使用了 Dynamo ,而关键业务上并未使用,看样子,这个工具还是有很多弱点,他们自己也清楚。