本文是笔者阅读 《Large-scale Incremental Processing Using Distributed Transactions and Notifications》 论文整理而得。
摘要
更新一个不断变更的搜索引擎的索引文档集合,是数据处理任务的一种常见场景,数据处理通过计算将一个个很小的页面转换为索引,当页面发生更改时,索引也需要更新。任务介于现在的基础设施之间:存储和计算。传统数据库已经不能存放 10PB 级别的数据,也不能在几千台机器中处理每天 10 亿次更新。MapReduce 和其他批处理系统不能处理仅有小部分增量更新的数据,因为他们适用于更大规模的数据量,小更新效率不高(相当于重跑 map-reduce 任务)。
Google 研发了 Percolator,可以处理大数据集里的增量数据更新,利用它来构建 Google Web 搜索的索引。使用 Percolator 替换批量数据处理后,相同的数据量,可以将文档平均年龄降低 50%。文档年龄(age of document)的大概意思是指文档从被爬虫抓取下来到能够出现在搜索结果的时长。
介绍
Google 搜索引擎爬取海量的 web 文档,这些文档会被构建成一个分布式的反向索引。构建是一个批处理任务,它需要解析文档内容和链接,然后根据 Page-Rank 对文档进行排列。使用相似性检测算法(比如 simhash)去重,去重时 Page-Rank 分值最高的需要保留(被引用次数越多的文档分值越高),其他都需要丢弃,这时就需要将链接替换,避免链接指向了被丢弃的页面或者文档。
MapReduce 属于离线批处理任务,它假定文档不会被修改,每个任务都不用担心 Page-Rank 高的页面被并发修改。
如果我们重新爬取了一部分 Web 文档,这部分文档的内容如何构建索引呢?重跑一次 MapReduce 任务非常耗时,而且本身新增受影响的页面也不多。使用传统的 DBMS 的事务来更新新增页面的索引也不现实,因为数据量非常庞大,DBMS 根本无法支撑。Bigtable 倒是可以支撑这么大的数据量,但是它没有提供多行事务,更新时会带来并发问题,导致数据错乱。
有一个理想的处理 Web 索引的模型叫增量处理(incremntal processing),它可以维护一个庞大的索引集群,同时还支持一边爬取内容一边高效更新索引。该增量处理将会并发的修改索引文档,还能保持数据一致性,可以跟踪哪些数据已经被处理。
本文要讲的增量处理系统就是 Percolator,它为用户提供 PB 级别的随机读写和更新,不需要 MapReduce 那样的全局扫描。Percolator 提供了兼容 ACID 的事务,基于快照的隔离级别。
除了需要关注并发,增量系统还会跟踪增量计算的状态。Percolator 提供观察者(observer),它就是一些回调代码块,当用户监听的列被修改时就会调用这串代码。Percolator 应用就是将一系列观察者结构化,每个观察者完成一个任务,然后通过更新表数据触发动作,推动下游观察者。外部流程是更新表数据时触发链式结构的第一个观察者。
Percolator 专为增量处理,并不是对现在大数据处理的补充。如果计算不能切分为一个个小的更新操作(分而治之),那么它就更适合 MapReduce,比如文件排序;而且如果计算不是强一致性要求,Bigtable 也足够使用。最后,计算量在多个维度会比较大,如果计算量小,传统的 DBMS 也足够使用。
在 Google 内部,Percolator 的主要应用就是准备实时更新搜索引擎的倒排索引。通过将索引系统转换为增量系统,我们可以单独处理爬下来的 Web 页面。它可以降低文档平均处理延时和文档平均年龄。
设计
Percolator 提供了两大抽象模型,一个是 ACID 事务模型,另一个是组织增量计算的观察者(observer)。
一个 Percolator 系统由三部分组成:Percolator 工作进程、Bigtable tablet server 和 GFS chunkserver。所有的观察者都被链接到 Percolator 的工作进程里,它扫描 Bigtable 被更改的列,然后以函数调用的方式执行对应的观察者逻辑。观察者执行事务的方式是调用 read/write RPC 到 Bigtable tablet server,然后 tablet server 又调用 GFS chunkserver 的 read/write RPC。Percolator 系统还依赖两个服务:时间戳服务和轻量级锁服务。时间戳服务提供严格单调递增的时间戳(所以它是单例的),事务模型中的快照隔离级别需要使用这个时间戳作为事务版本号。工作进程使用轻量级锁服务提高脏数据通知效率。
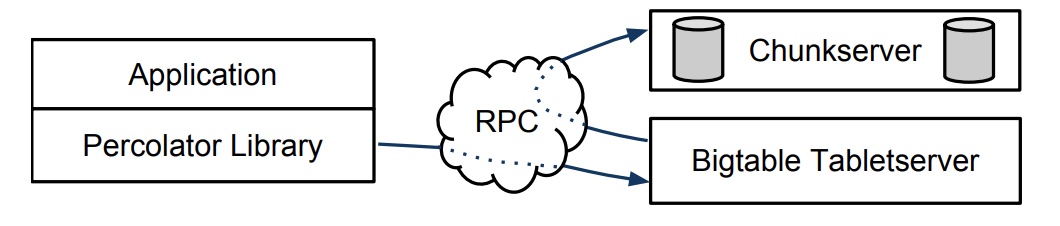
图-1 Percolator 和它的依赖
站在开发者的角度来看,Percolator 存储系统由一个个小的表组成,每个表都是由一个个小格子 cell 组成,一个字节数组用来表示它的值。在内部,为了支持快照隔离级别,我们将每个 cell 都当作一系列的时间戳索引的数据,时间戳作为数据的版本号。
Percolator 的设计受到两个因素的影响:
- 大规模数据量
- 不要求极致的低延迟
宽松的延迟需求可以让我们使用懒惰模式去清理失败事务的锁,懒惰模式实现简单,可能会将事务的提交延迟几十秒。对于 OLTP 类型的 DBMS 系统,这种延迟不能接受,但是对于构建索引文档集合的增量处理系统已经足够。Percolator 没有中心化的事务管理机制,缺少死锁检测,这种设计会增加事务冲突的延长时间(有锁等待的情况),但是却可以支撑大规模数据处理。
Bigtable 简介
Percolator 构建在 Bigtable 分布式存储系统之上。Bigtable 对用户提供多维度的 map 数据结构:key 是 (row, column, timestamp) 元组,key 按照从小到大排序。Bigtable 提供了查找和更新行的操作,而且基于行的操作是 read-modify-write 原子操作,最小事务,或者说修改一行的数据就是一个原子操作。Bigtable 可靠的运行在由大量机器组成的集群上,而且处理着 PB 级别的数据。
一个运行的 Bigtable 由多个 tablet server 和 一个 master 组成。master 管理和协调 tablet server 加载和卸载哪些 tablet;tablet server 为 tablet 提供服务,一个 tablet 就是一系列 SSTable 格式的文件组成,是一块连续区域的键空间。SSTable 文件存储在 GFS;Bigtable 依赖 GFS 可靠的存储能力。BigTable 允许用户优化查询性能:将一组相关联的列放在一个 locality group,这些列会存放在一个 SSTable 文件(或者文件集合)中。由于其他列不在 locality group 对应的 SSTable 文件,这样就可以避免多余的磁盘文件扫描,提高查询速度。
将数据存储在 Bigtable 就塑造了 Percolator 的特性。Percolator 维护着 Bigtable 的接口:数据存放在 Bigtable 的行和列,Percolator 自己的元数据存储在一个特殊的列里(如图-5所示)。Percolator 的 API 与 Bigtable 的 API 非常相似:Percolator 特殊的元数据所在的列的操作接口就是将 Bigtable 的大多数 API 封装了一层。最具挑战的就是提供了 Bigtable 不具备的多行事务和观察者框架。
分布式事务
Percolator 提供跨行跨表的快照隔离级别的事务。Percolator 用户使用特定的语言来编写事务代码(当前是 C++),中间再穿插 Percolator API 代码。下面的代码块是一个对文档做 Hash 计算的简单版本代码。
1 | bool UpdateDocument(Document doc) { |
代码块-1 文档更新
在这个例子中,如果 Commit() 方法返回 false,表示事务有冲突(此例中,因为两个相同 Hash 的 URL 同时处理了 ),需要退避后再继续重试。调用 Get() 和 Commit() 会阻塞;提高并行度的方式是在线程池内执行多个事务。
增量数据处理任务也可以不使用强事务,事务可以让开发变得简单,避免将错误引入到一个长期存活的数据系统中。比如,在一个事务性的 Web 索引系统中,开发者可以假设文档内容 hash 与构建的索引数据完全一致。如果没有事务,系统抽风了的时候就会导致永久错误,文档内容与构建的索引数据不一致。事务也可以很轻松的让构建的索引一直保持最新且一致。注意,这个例子需要的事务能够跨行,而不仅仅是 Bigtable 能提供的单行级别的事务。
Percolator 使用 Bigtable 的 timestamp 来存储数据的多个版本。多版本需要提供快照级别的隔离性,表现的就是在一个 timestamp 所读到的数据都是一致的,因为它只会读取比当前 timestamp 小的数据。写操作就需要一个更大的 timestamp。快照隔离可以避免写-写冲突:如果两个事务同时写入同一个 cell 的数据,最多只有一个事务能写成功。快照隔离相比序列化隔离级别的优点是更高效的读操作,因为通过 timestamp 获得的一致性快照视图,对于读取操作是不需要加任何锁的。
Percolator 使用 Bigtable 来实现分布式锁,锁存在一个特殊的 Bigtable 内存列中,事实上存储锁和数据的 Bigtable 实例都是同一个,访问 Bigtable 数据时涉及锁的读取和修改。使用 Bigtable 实现的分布式锁具有如下特点:
- 高可用
- 分布式
- 负载均衡
- 持久化
1 | class Transaction { |
代码块-2 Percolator 事务伪代码

图-2 Percolator 事务状态转移1: Bob 转 7 美元给 Joe

图-3 Percolator 事务状态转移2: Bob 转 7 美元给 Joe

图-4 Percolator 事务操作的列
代码块-2 是 Percolator 的分布式事务的伪代码,图-2和图-3是 Bob 像 Job 转 7 美元的分布式事务数据状态变化流程,图-4是事务操作的列以及其含义和用法。
Transaction 事务开启时在构造函数内会调用 timestamp oracle 获取一个时间戳,在快照隔离级别下,它决定了 Get() 方法能看到的哪些版本的数据。调用 Set() 方法时会将操作缓存起来,当 Commit 时再提交。提交缓存操作是一个“二阶段提交”,由客户端协调事务。
第一阶段是 Prewrite 预写阶段,Percolator 会锁住所有需要写入的列。为了处理客户端失败,Percolator 任意指派一个锁为 primary 锁。事务会读取所有需要被写的 cell 的元数据来检查是否存在冲突。
有两种发生冲突的元数据:
- 事务开始后,还发现其他事务写入了记录,取消本事务,见代码块-2的第 32 行。这是快照隔离保护的写-写冲突;
- 事务还能看到锁,取消本事务,见代码块-2的第 34 行。发生这种情况有三种可能;1)事务释放锁的速度太慢;2)设置锁的事务的客户端挂了;3)并发操作。
如果没有冲突时,事务给每个 cell 写入锁和记录,记录的时间戳是事务开始时间,见代码块-2的第 37 行到第 39 行。
以上是第一个阶段的逻辑。
如果 Prewrite 执行成功,也就是没有遇到任何冲突时,开始执行第二阶段,从第 48 行开始。
第二阶段的逻辑是这样的。Percolator 再次从 timestamp oracle 获取提交时间戳(注意一个事务需要两次获取时间戳,一次是事务开启时,另外就是本次)。从 primary 锁开始,客户端给每个 cell 都释放锁,同时将记录写入 cell 中并设置刚获取的提交时间戳,这表示数据对其他用户可见。见图-3中的第4步。
对于 Get() 操作来说,事务先检查当前 cell 中是否存在锁,如果有说明有事务正在操作这个 cell,此时需要等待直到锁释放。如果没有锁冲突,Get() 就读取最新写入的数据时间戳,然后找到对应的数据,见代码块-2的第 19 行和第 22 行。
由于客户端处理事务可能失败,此时锁就可能一直存在,造成后面的事务永远阻塞。因此新开启的事务需要检测锁是否有效,如果无效就需要清除,以便事务继续执行。检测锁是否有效的方法是依靠 primary 锁,这在前文中多次提到。每个事务都是由 primary 锁来协调的,不仅有 primary 会记录锁,其他 cell 也会记录 primary 锁的位置。通过找到 primary 锁,然后判断持有 primary 锁的客户端是否还存活来决定锁是否有效,如果客户端挂了,那么事务就可以清除锁,否则一直等待。判断客户端是否存活的方式是通过 Chubby 服务来完成的,类似 Zookeeper 一样的组件,或者的组件会注册进来,否则会移除。由于 Bigtable 单行事务特性,清除事务和提交事务只有一个操作能完成。
还有种情况是 primary 提交成功但是 secondary 没有提交成功,这种情况下需要让事务恢复并且继续执行下去,因为 primary 提交意味着事务以及完成,其他用户都可以读到记录了。如果 primary 还没有提交时,直接回滚。
时间戳
Percolator 使用 timestamp oracle 的单调递增时间戳来实现快照隔离的事务。timestamp oracle 只有一个节点提供授时服务,为了保证高可用、高吞吐量,并且节点失败时时间戳依然是严格的单调递增,timestamp oracle 会周期性的分配一个时间戳范围,同时将最大时间戳保存起来,比如保存在数据库。timestamp oracle 就可以直接在内存中高效的处理授时请求。当 timestamp oracle 节点崩溃时,其他节点从数据库中读取最大的时间戳,同样是周期性的分配一个时间戳范围,保存最大时间戳,并继续提供授时。获取的时间戳是不会回拨的。
此外,Percolator 还会进行批处理优化,即合并请求,一次获取多个时间戳。一个 timestamp oracle 可以完成 200 百万次请求。
Percolator 事务使用 timestamp oracle 严格的单调递增特性保证 Get() 获取已提交的数据早于本事务开始时间戳。实现逻辑也比较简单,假设读事务 R 开始时间是 Tr,事务 W 写数据时间是 Tw,且 Tw < Tr,通过比较时间可知事务 R 可以读到事务 W 写入的数据。
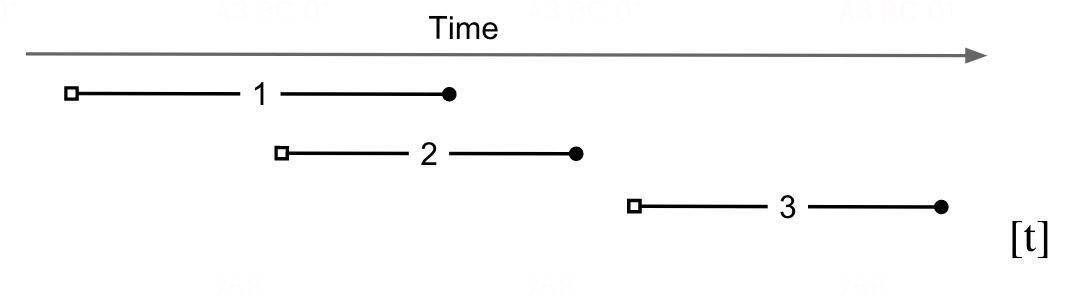
图-5 快照隔离
图-5所示,快照隔离级别下的读事务始于事务开始时间戳,使用空心方块表示,写数据时使用的是提交的时间戳,使用实心小圆表示。在代码块-2中分别用 start_ts_ 和 commit_ts 来表示事务开始时间戳和事务提交时间戳。图-5这个例子中,事务2不会看到事务1写入的数据,因为事务2的开始时间戳早于事务1提交时间戳。但事务3可以看到事务1和事务1写入的数据,因为事务3开始时间晚于事务1和事务2提交的时间戳。
通知
在 Percolator,用户写的代码称为 observer,当表被修改时它就会被触发。每个 observer 注册一个函数和声明需要关注的列,当这些关注的列(observed column)的数据变更时就会触发函数。Percolator 应用是由一系列 observer 组成,每个 observer 在完成一个任务时还会为下游的 observer 创建任务,这样形成一个链式反应。通知的目的是帮助实现增量计算而不是做到数据完整性。
Percolator 会保证每次 observed 列更改时最多只有一个 observer 的事务可以提交成功。为了减少通知次数,Percolator 使用 message collapsing 机制(相当于消息合并),周期性的通知客户端程序执行业务逻辑,而不是数据一修改就通知,这样造成频繁的数据更新,锁冲突也会加大。
每个 observer 的每个关注的列都有一个 ack 列,它记录了上次运行 observer 的时间。当 observed 列被修改时,Percolator 就会启动一个事务来处理通知,事务读取 observed 列和对应的 ack 列,如果 observed 列的写入时间晚于 ack 列记录的时间,Percolator 就会运行 observer 并且在 ack 列上记录新的事务的时间。否则就意味着事务已经执行,不需要再执行了。如果在一次通知中意外地同时执行两个事务,两个事务都会执行 observer 代码,但是只有一个会成功,因为他们会因为 ack 列而发生冲突,肯定有个事务会更新失败而放弃执行。
为了实现通知机制,Percolator 在每次写数据时都会在一个特定的 notify 列记录下来,记录内容的是哪个 cell 被修改了,然后不断的扫描这个列的数据,找到更改的 cell,然后开始执行 observer 代码,当 observer 执行成功并且 commit 后就会将 notify 列的记录清除。由于 notify 列是 Bigtable 列而不是 Percolator 列,意味着它没有事务特性,它仅仅是为了扫描脏数据,然后检查 ack 列是否有必要执行 observer 代码。
由于 Percolator 存储的数据量非常的大,并且修改的操作也会非常多,为了提高扫描的性能,Percolator 将 notify 列存储在一个单独的 Bigtable 本地组(locality group)内,这样每次扫描后就只需要读到 notify 数据,而不会读取业务数据。每个 Percolator 工作实例都会使用几个线程来执行扫描操作,每个线程扫描 table 的一部分,第一次执行是都是随机挑选一个 tablet,然后随机选择一个键空间,然后从这个位置开始扫描。为了避免同时扫描同一个区域的数据,Percolator 使用一个轻量级锁来控制。当扫描的线程发现其他线程也在扫描这一行时,这个线程就会重新随机选择一个位置,然后继续执行扫描任务。
为了减少事务冲突,Percolator 引入了弱事务的概念。它的实现方式是只向 notify 列写数据。为了保留 Percolator 其他事务语义,将弱通知限制在某个特殊的列上,不能写,只能被通知。
讨论
Percolator 相对于 MapReduce 来说并不高效,因为 Percolator 每次事务处理都涉及大量的 RPC 操作,不想 MapReduce 一次性可以处理大量的数据,而 Percolator 处理的数据量就比较少。为了减少 RPC 调用,提高效率,Percolator 优化了 Bigtable 的 read-modify-write 需要两次 RPC 调用的逻辑,改成只需要一次 RPC 调用,相当于 CAS。
为了进一步提高数据处理效率,Percolator 使用批量处理,包括获取锁的批量操作和读取数据的批量操作(仅限同一个 tablet)。最后一个优化是预取 prefetching。由于每次从 Bigtable 读取数据时,Bigtable 就会读一个 chunk 内的大量数据了,所以通过预取将数据缓存在 Percolator 也能提高效率。需要预先读取哪些数据采用的是启发式的方法,即根据历史记录自动学习。