本文是作者阅读了《Is Parallel Programming Hard, And, If So, What Can You Do About It?Second Edition》 一书的附录C “Why Memory Barriers” 整理出来。篇幅较长,请耐心阅读。
为什么 CPU 设计者要设计内存屏障呢,简单回答就是指令重排序的内存引用具有更高的性能,需要引入内存屏障来解决类似同步原语(synchronized primitives)这类的顺序读写内存操作。要想完全搞清楚这个问题,需要理解 CPU 的缓存 cache是如何工作的,特别是要需要清楚的知道怎样操作才能让缓存利用更加高效。
本文包括:
- Cache 的结构;
- 缓存一致性协议(cache-coherency protocol)确保 CPU 能读写同一个内存数据;
- store buffer 和 invalidate queue 帮助缓存和缓存一致性协议达到更高的性能;
Cache 结构
现代的 CPU 处理速度远快于现代的内存系统,一个 2006 年产的 CPU 每纳秒可以执行 10 个指令,但是需要 10+ 纳秒(tens of nanoseconds)才能从内存里拿出一个数据。这种速度不相称的情况就造成了现代 CPU 会有多个 Cache,每一核关联一个 Cache。如图-1所示。
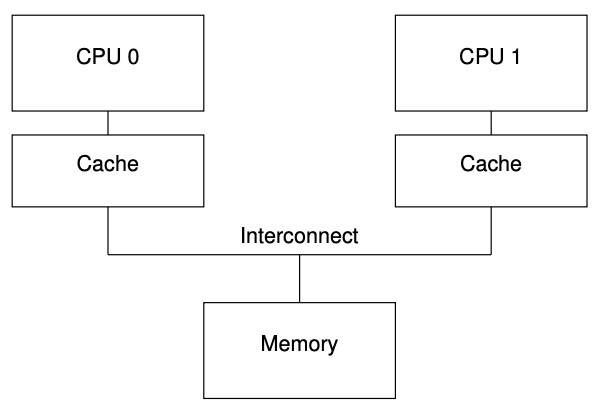
图-1 现代计算机系统的缓存结构
数据以固定大小的块从内存流转到 cache ,这个固定大小的块就是缓存行(cache line),它是 2 的幂次,范围从 16 到 256 字节不等。当一个 CPU 第一次读取一个数据时,这个数据必定不在缓存内,称为缓存失效(cache miss,还可以细分为 startup 缓存失效和 warmup 缓存失效)。缓存失效意味着 cpu 需要等待多个时钟周期去内存中加载数据。由于数据是被加载到 cache 缓存,所以读取后续的数据能够命中缓存,能以最快的速度执行。
CPU 运行一段时间后,cache 会被数据填满,此时又需要将 cache 内的旧数据移除,以便腾出空间存储最新读取的数据。这被称为容量失效(capacity miss),因为这是由于 cache 容量限制导致的。事实上,很多旧数据被移除时,并不需要等到 cache 缓存被填满,当某些缓存行还有空间剩余时,旧的数据也需要被移除,腾出空间给新来的数据。这是因为 cache 被设计成一个硬件类型的 hash 表,hash 表有固定大小的 hash 桶(hash bucket,或者组 set),非链式结构,如图-2所示。
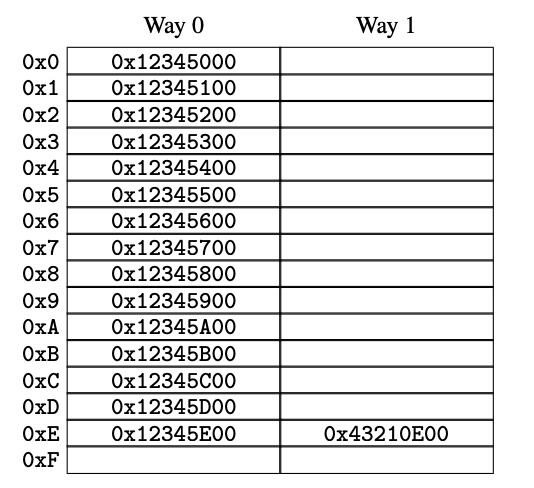
图-2 缓存结构
图-2所示是两路组相联的 cache (a two-way set-associative cache),每一路有16组,合起来就是 32 个缓存行,每一个格子就包含了 256 字节的缓存行,按 256 字节对齐。缓存行大小按这种方式对齐,对于十六进制计算非常简单。这种硬件实现的 hash 表,我们可以把它与软件实现的 hash 表做个类比:软件 hash 表有 16 个 hash 桶,每个桶有最多两个元素的链表。由于缓存 hash 表是由硬件实现,hash 函数非常简单,就是从内存地址中取 4 位。
图-2所示的缓存有 32 个格子,每个格子就是一个 256 字节大小的缓存行。有些格子还是空的,有些格子已经被填满。填满的标记是一个内存地址,表示该缓存行存储的数据是这个内存地址开始到256字节结束的数据。因为缓存行必须按照 256 字节对齐,所以缓存行的的首地址的低8位都是0,硬件的缓存 hash 算法就采用下一个4位作为缓存行的索引。
以图-2为例举一个场景来说明缓存行的工作模式。某一个程序代码的地址是从 0x43210E00 到
0x43210EFF,这个程序顺序的从 0x12345000 到 0x12345EFF 的数据。假如这个程序现在要读取地址 0x12345F00 的数据,根据 hash 函数可以算出这个地址的缓存行是 0xF,而图-2所示的 0xF 缓存行的两路格子都是空的,所以这个内存地址的数据可以直接存放在缓存行内。如果这个程序要读取地址 0x1233000 ,根据 hash 函数可以算出这个地址的缓存行是 0x0,这个地址的数据支持存储在右边那个格子上,因为只有这个格子是空的。但是如果程序要读取 0x1233E00 这个地址的数据,根据 hash 函数算出缓存行是 0xE,现在这两个格子都填满了数据,需要将其中一个格子的数据清空,用来存放 0x1233E00 这个地址的数据。如果被清空的地址后面又被读取,此时又会出现缓存失效的情况。
到目前为止,我们讨论的都是读取缓存的问题,那么对于写缓存会发生哪些事情呢?最重要的是要让多核 CPU 都认同一个数据为同一个值,当一个 CPU 准备写入一个数据时,它需要先通知其他 CPU 将其缓存失效或者移除。如果其他 CPU 已经使数据失效或者移除,这个 CPU 就可以将数据写入到自己的 CPU 缓存中。使用读、写会造成一个数据在多个 CPU 中会有不同的值,而失效操作会使得其他 CPU 的数据丢失。要解决这些问题就需要缓存一致性协议。
缓存一致性
缓存一致性协议管理缓存行的状态,以便防止数据丢失和不一致问题。缓存一致性协议非常复杂,有几十种状态,但在本节只会讲常用的4种,即 MESI 。
MESI 状态
MESI 代表 “modified”(修改),“exclusive”(独占),“shared”(共享) 和“invalid”(失效),他们表示缓存行的状态。这4种状态可以用2位来表示,每一个缓存行就是物理内存地址+数据+2位状态标签。
“modified”状态的缓存行表示它的数据已经被修改,准备写回到内存,其他的 CPU 没有这份内存数据,也就是说 CPU 拥有这块内存的数据独占资源,因此它有最新数据的一份拷贝。这种状态的CPU职责有两个,一个是准备写回到内存,另一个就是写回前被其他CPU读走,其他CPU拥有独占资源。
“exclusive”与“modified”非常相似,唯一的不同是 CPU 还未修改缓存行,它表示 “exclusive”状态的缓存行拥有最新数据的一份拷贝。“exclusive”状态的缓存行也意味着 CPU 独享,它可以在任意时刻对这个缓存行再次修改,其他 CPU 缓存没有这份数据的拷贝。由于“exclusive”状态的缓存行是未被修改的数据,所以它无需写回到内存。
“shared”状态的缓存行表示缓存行至少有2个CPU都共享了这些数据。所以当一个 CPU 想要修改缓存行数据时,必须要提前向其他 CPU 查询一下,不允许直接修改。“shared”缓存行对应的内存数据是最新的,也不需要写回到内存。
“invalid”状态的缓存行表示数据是空的,也就是这个缓存行没有数据。如果数据要想放到缓存行,缓存行的状态最好是“invalid”状态。如果是其他状态,会出现昂贵的缓存失效操作,因为这部分数据后面大概率会被访问。
因为说有的 CPU 都需要保持数据一致性,缓存一致性协议提供了协调缓存行状态移动的消息。
MESI 协议消息
MESI 的状态转移需要多个 CPU 之间进行通信,对于一个共享总线的计算机系统,需要用到这些消息:
- Read:向缓存行发起读取一个物理地址数据的操作;
- Read Response:响应 Read 消息的结果,Read Response 可能是内存响应,也可能是其他CPU的缓存行响应。如果一个缓存行的状态是“modified”并且包含 Read 请求的数据,该缓存行必须响应这个 Read 请求;
- Invalidate:发起让一个包含指定物理地址的缓存行失效的请求,所有的CPU缓存都必须清除这个物理地址的数据;
- Invalidate Acknowledge:一个CPU收到 Invalidate 后清除了数据就必须回复 Invalidate Acknowledge 消息;
- Read Invalidate:是 Read 和 Invalidate 两个操作的合并,发起一个 Read 请求后还需要向其他CPU发起 Invalidate 请求,它需要搜到两种类型的消息回复,一个是 Read Response ,另一个是 Invalidate Acknowledge;
- Writeback:写回的消息包含了写到内存的物理地址和数据,这个消息可以将“modified”状态的缓存行失效,释放空间用来存储其他数据;
MESI 状态图
当一个缓存行发起和接收MESI消息时,它的状态变化如图-3所示。
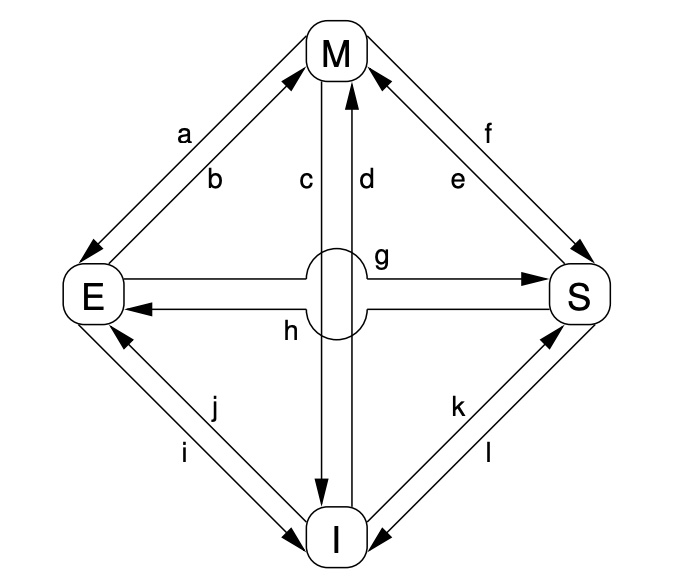
图-3 MESI 缓存一致性状态图
每条线的状态转移过程如下:
- a :缓存行写回到内存但是还要继续保留缓存行的修改权限,这个状态转移需要 Writeback 消息;
- b :CPU 向独占(exclusive)的缓存行发起写操作,这个状态转移不需要任何消息;
- c :发生在当一个“modified”状态缓存行的CPU收到 Read Invalidate 的请求时。CPU必须清空这个缓存行的数据,并且回复 Read Response 和 Invalidate acknowledge 消息,这两个消息都需要发送到请求的CPU,表示这个CPU不再拥有这份数据;
- d :一个CPU对一个数据项执行了“read-modify-write”原子操作,而这份数据又不在缓存行中。CPU发起一个 Read Invalidate 消息,然后需要收到内存或者其他CPU的 read response 消息,如果这个CPU还收到了 Invalidate Acknowledge 消息后,它就可以完成这个原子操作的状态转移。
- e :一个CPU对一个已存在缓存行中的只读数据项发起了“read-modify-write”原子操作。必须先发起一个 Invalidate 消息,然后等所有的CPU都回复了 Invalidate Acknowledge 消息才能完成这个状态转移。
- f :一个CPU读另一个CPU的缓存行,这个缓存行已完成写回内存且保持只读。要完成这个状态转移首先这个CPU需要接收到一个 Read 消息,然后此CPU回复 Read Response 消息。
- g :一个CPU读另一个CPU的缓存行,响应这个读操作可能是来自内存或者是另一个CPU的缓存行,不管哪种方式,另一个CPU的缓存行依然保留这份只读数据的。这个转换首先是缓存行接收到了 Read 消息,然后响应 Read Response 消息。
- h :CPU意识到它将要立马写一些数据到一个缓存行,因此发起一个 Invalidate 消息,直到它所有了其他所有CPU的 Invalidate Acknowledge 消息才能完成这个状态转移。相应地,其他CPU收到这个 Invalidate 消息后需要将数据写回到内存(如果有脏数据),然后从缓存行删除这些数据,可以腾出空间给其他数据。最后就只有发起 Invalidate 消息的这个CPU缓存了这份数据。
- i :其他CPU对当前缓存行持有的数据项执行了“read-modify-write”操作,当前缓存行需要从这个CPU上失效。这个状态转移首先是这个CPU收到了 Read Invalidate 消息后,然后回复 Read Response 和 Invalidate Acknowledge 消息。
- j :CPU要写一份数据到缓存行,由于要独占,因此需要发起 Read Invalidate 消息,直到收到 Read Response 且所有其他的CPU都回复了 Invalidate Acknowledge 才能完成状态转移。可以通过 b 完成 exclusive 到 modified 的状态转移。
- k :CPU发起 Read 消息读取一项数据到缓存行,收到 Read Response 即可完成状态转移。
- l :其他CPU将一项数据存储到缓存行,这项数据目前正存储在当前CPU的缓存行。状态转移发生在CPU收到 Invalidate 消息后,该CPU回复 Invalidate Acknowledge 消息。
MESI 协议举例
为了简单起见,我们使用一个4核CPU,每个CPU只有一个缓存行来举例。首先,缓存行的数据一开始是放在内存0地址上。如图-4所示,表格显示了缓存行和内存之间的数据流,第1栏是每个操作的序号,第2栏是CPU执行这个操作的CPU编号,第3栏是操作的名称,第4栏是CPU缓存行的状态,最后两栏表示的是内存数据是否是最新的,V 表示最新,I 表示不是最新。注意表-4中的 Load 和 Store 针对的都是缓存行,Load 表示加载数据到缓存行,Store 表示修改缓存行或者写数据到缓存行。
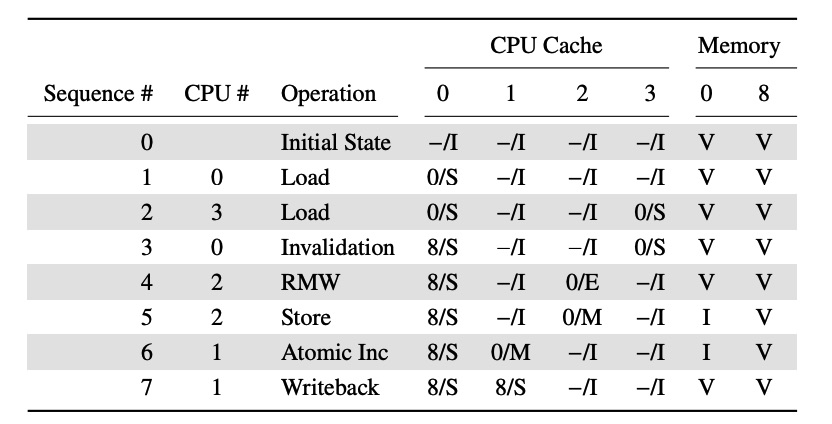
图-4 MESI 缓存一致性举例
首先,CPU缓存行都是空的,状态是“invalid”,数据在内存中的状态是“valid”,表示内存中的数据是最新的。当0号CPU从地址0加载数据,它进入到0号CPU缓存行,状态为“shared”,此时内存中的数据依然是最新的。第3号CPU也从地址0加载这项数据,所以这两个CPU都有一份共享的数据,状态都是“shared”,内存中的数据还是最新的。
接着,0号CPU读取地址8的数据到缓存行,由于缓存行空间不够,本操作强制将缓存行中的数据清空,填充地址8的数据。2号CPU也从0地址加载数据,它意识到自己将要立马修改这个缓存行,所以它使用 Read Invalidate 消息以便自己能获得数据独占的要求,因此将3号CPU包含0地址的缓存行数据清空。然后2号CPU执行下一个 Store 指令,将它的修改对应的缓存行数据,此时缓存行的状态是“modified”状态。此时内存中的数据已经不是最新的数据,缓存行的数据才是最新的。
1号CPU执行一个原子自增操作,需要使用 Read Invalidate 消息探测一下其他CPU是否有地址0的数据,此时2号CPU它正好有1号CPU需要的数据,因此2号CPU需要回复 Read Response 消息,与此同时,还要将自己的数据清空,回复 Invalidate Acknowledge 消息。现在1号CPU的状态是“modified”状态,对应内存的数据也不是最新的。
最后,1号CPU通过 Writeback 消息将数据写入到地址0,然后读取地址8的数据到缓存行。
Store Result in Unnecessary Stalls
标题可能翻译不准,保留英文原文,含义是“不停顿地保存结果”。
尽管图4中的CPU结构对于一个CPU重复读写给定数据有很好的性能,但是对于第一次写数据时,性能会比较糟糕。图-5所示是 CPU 0 写操作的一个时间线,当CPU 0要写的缓存行数据存在 CPU 1 时,需要先获得缓存行的独占资源,因此需要向 CPU 1 发起 Read Invalidate 消息,CPU 1 回复 Read Response 消息和 Invalidate Acknowledge 消息时,CPU 0才能完成“exclusive”状态,这样才能写数据。而等待 Read Response 和 Invalidate Acknowledge 需要花一定的时间。
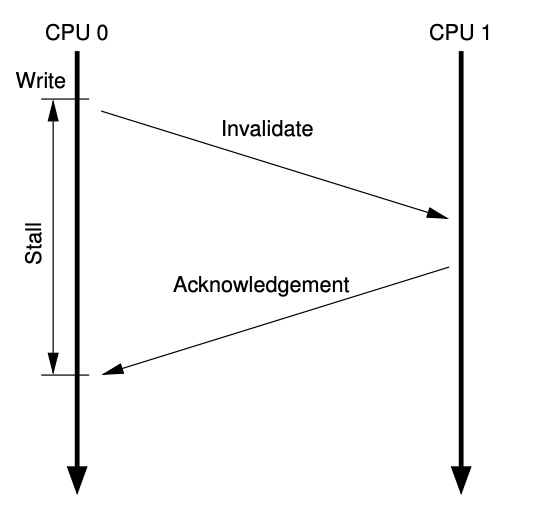
图-5 非必要的写停顿
然而我们也没有必要真的让CPU 0等待那么长时间,毕竟,不管CPU 1发送了什么数据到这个缓存行,CPU 0都会无条件的覆盖它。
Store Buffers
store buffer 可以翻译为缓存行写缓存区,不过本文依然使用英文 store buffer 来表示,不用中文表达。
有一种阻止没必要写停顿的方法是在CPU和缓存之间加一个 Store Buffers,如图-6所示。
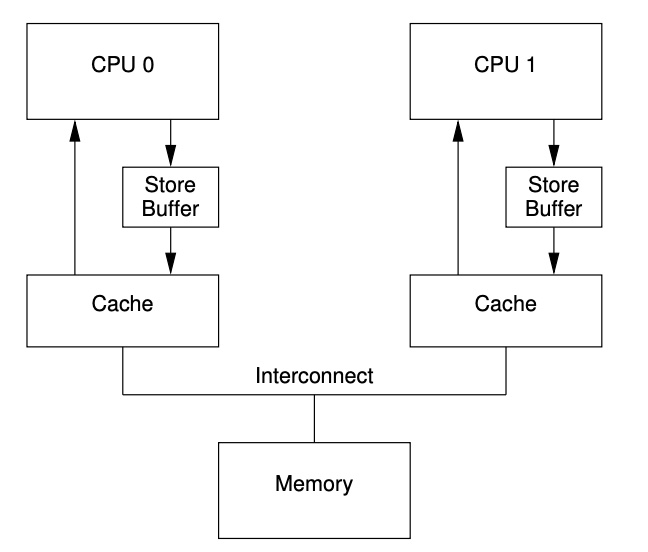
图-6 带有 store buffer 的缓存系统
加上额外的 store buffers 后,CPU 0 就可以简单的将操作记录存到 store buffers,然后继续执行后面的操作。比如 i = 5 这种写就可以先将其结果记录在 store bufffers,不管其他 CPU 存的 i 是多少,这个 CPU 都是会忽略的。当该数据项对应缓存行的独占资源从 CPU1转移到 CPU 0 时,之前记录在 store buffers 中的数据就可以移出写到这个缓存行中。
store buffers 是 CPU 局部独有非共享,也可以是硬件虚拟的一核多线程环境中被这一核局部独有。不管是哪种方式,CPU 只能访问它自己的 store buffers。比如图-6中的CPU 0不能访问CPU 1的 store buffer,反之亦然。这种限制通过分而治之的方式简化了硬件设计:store buffer 提高连续写的性能,CPU之间通过缓存一致性协议通信。
然而,尽管有这个限制,也还是有很多复杂的问题需要提出来,下面两节讨论。
Store Forwarding
第一个复杂的问题是违反 self-consistency ,先看下面的代码:
1 | a = 1; |
假设,变量 a 和变量 b 都初始化为 0,变量 a 首次放在 CPU 1 的缓存行,变量 b 首次放在 CPU 0 的缓存行。
代码简单,没有人认为断言会失败。然而,如果有人足够幼稚的使用图-6这种简单架构来考虑问题,惊喜来了。这个系统可能会出现下面这串事件:
- 1 CPU 0 开始执行
a = 1; - 2 CPU 0 在缓存中查找
a,发现它不存在; - 3 CPU 0 因此发送 Read Invalidate 消息一致获得变量
a缓存行的独占权; - 4 CPU 0 将
a = 1结果记录到 store buffer; - 5 CPU 1 接收到 Read Invalidate 消息,然后回复
a缓存行的数据,即发生消息 Read Response,同时还会把a缓存行的数据失效,然后回复 Invalidate Acknowledge 消息; - 6 CPU 0 开始执行
b = a + 1; - 7 CPU 0 接收到 CPU 1 回复的缓存行数据,
a现在依然是 0; - 8 CPU 0 将
a从缓存行读取,放入到计算逻辑单元寄存器,准备做a + 1的计算 ,此时a的值是0; - 9 CPU 0 将 store buffer 存储
a的条目取出应用到新来的a缓存行,将缓存行中a的值设置为 1; - 10 CPU 0 接着第8步,将 1 和值为 0 的
a相加,然后将结果 1 存入到b的缓存行中(注意我们一开始就是假设b放在 CPU 0 的缓存行中); - 11 CPU 0 执行
assert(b == 2)时,断言失败;
造成失败的原因是 a 有两份拷贝,一份是缓存行,另一份是 store buffer。
这个例子打破了一个很重要的规则,这个规则保证每个CPU都能看到它的操作就好像是程序顺序执行的结果一样。打破这个保证对于软件类型来说是粗暴违反自觉的,以至于(so much so that)硬件设计者想出一个技巧,实现“store forwarding”,之后每个CPU加载数据到缓存行时都需要检查 store buffer 有没有数据,如图-7所示。换言之,一个给定的CPU的 store 操作是直接转到接下来的 load 操作,中间不再需要经过缓存行。
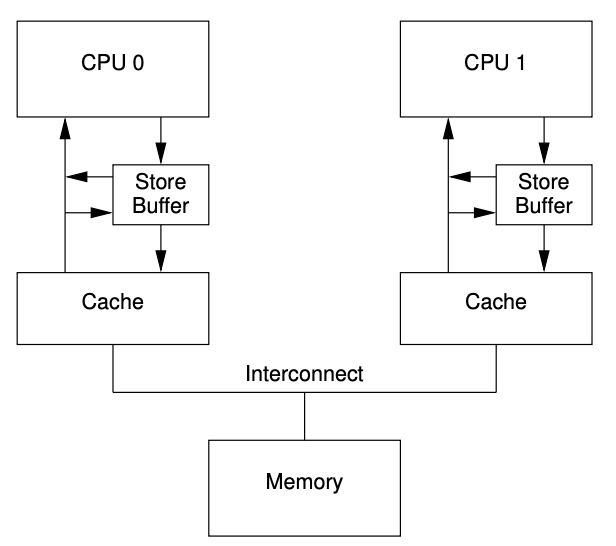
图-7 带有 store forwarding 的缓存系统
使用 store forwarding 后,在第8步的时候就会发现 a 的正确值 1 存在 store buffer 中,所以 b 的最终结果将会是 2 ,这也是期望的值。
store buffers 和内存屏障
再来看看第二个复杂的问题,一个违反全局内存顺序的问题,看看下面代码,一开始 a 和 b 都初始化为0:
1 | void foo(void) |
假设 CPU 0 执行了 foo() 方法,CPU 1 执行了 bar() 方法,又假设 a 的缓存行存在 CPU 1 中,b 的缓存行存在 CPU 0 中。然后接下来的一串操作可能如下:
- 1 CPU 0 执行
a = 1。由于CPU 0没有a的缓存行,所以 CPU 0 将a = 1的结果放在 store buffer 中,然后发起 Read Invalidate 消息。 - 2 CPU 1 执行
while(b == 0) continue,但是保存b的缓存行不在 CPU 1中,所以CPU 1发起 Read 消息。 - 3 CPU 0 执行
b = 1,它已经拥有b的缓存行(换言之,这个缓存行可能处于 “modified” 或者 “exclusive” 状态)。 - 4 CPU 0 收到 Read 消息,CPU 0 将
b缓存行最新修改的数据发送给 CPU 1,同时将b缓存行的状态更改为 “shared”。 - 5 CPU 1 收到
b缓存行的数据并将b缓存行的数据放在自己的缓存中,此时b的值是 1。 - 6 CPU 1 可能线程完成了
while(b == 0) continue操作,结束了while循环,因为它发现b的值是 1,所以接着持续下面的操作。 - 7 CPU 1 执行
assert(a == 1),因为 CPU 1 拿到的a还是旧值,所以断言失败。 - 8 CPU 1 收到 Read Invalidate 消息,然后将
a的缓存行数据回复给 CPU 0,然后将a的缓存行从 CPU 1中移除,但是它太晚了。 - 9 CPU 0 收到
a的缓存行,然后将 store buffer 中暂存的a值覆盖掉缓存行。它是 CPU 1 断言失败的罪魁祸首。
硬件设计者不能直接解决这个问题,因为 CPU 无法理解变量之间的联系。因此硬件设计者提供了内存屏障的指令,允许软件开发者告诉 CPU 这种关联关系。上面的程序代码需要更新为包含内存屏障的代码,如下:
1 | void foo(void) |
内存屏障函数 smp_mb() 将会让 CPU 在执行接下来的指令前刷新 store buffer 的数据到变量的缓存行。CPU 要么就暂停直到 store buffer 清空然后再执行,要么它利用 store buffer 保存接下来的 store 直到所有之前的条目都已经刷到缓存行。
使用内存屏障后,这串代码的一系列操作可能是:
- 1 CPU 0 执行
a = 1。由于CPU 0没有a的缓存行,所以 CPU 0 将a = 1放在它的 store buffer 中,然后发起 Read Invalidate 消息。 - 2 CPU 1 执行
while(b == 0) continue,但是保存b的缓存行不在 CPU 1中,所以CPU 1发起 Read 消息。 - 3 CPU 0 执行
smp_mb(),标记当前所有的 store buffer 条目,也包括a的值 1。 - 4 CPU 0 执行
b = 1,它已经拥有b的缓存行(换言之,这个缓存行可能处于 “modified” 或者 “exclusive” 状态),但是发现 store buffer 已经有标记的条目。因此并不是将b的新值 1 存储到缓存行,它也将b的值放在 store buffer 中,b的条目不需要标记。 - 5 CPU 0 接收到 Read 消息,它将包含
b缓存行的数据发送给 CPU 1,并将自己的缓存行副本状态标记为 “shared”。 - 6 CPU 1 收到
b缓存行的数据并将它放在自己的缓存行。 - 7 CPU 1 现在可以拿出
b的值,但是发现b的值依然是 0,继续重复while循环。b的新值现在正安全的保存在 CPU 0 的 store buffer 中。 - 8 CPU 1 收到 Read Invalidate 消息,它将
a缓存行的数据发送给 CPU 0,然后清除a缓存行。 - 9 CPU 0 收到
a缓存行的数据,然后应用a的 store buffer 到缓存行,更新缓存行的状态是 ”modified“ 状态。 - 10 因为
a是唯一一个被smp_mb()标记的条目,所以 CPU 0 也可以存储b的新值,但是包含b缓存行的状态是 “shared”。 - 11 CPU 0 因此需要发送 Invalidate 消息给 CPU 1。
- 12 CPU 1 收到 Invalidate 消息,将包含
b缓存行的清除,然后回复 CPU 0 一个 Invalidate Acknowledge 消息。 - 13 CPU 1 执行
while (b == 0) continue,但是b不在缓存行中,因此向 CPU 0 发起 Read 消息。 - 14 CPU 0 收到 Invalidate Acknowledge 消息,将
b缓存行的状态更改为 “exclusive” 状态,CPU 0 现在可以更新b的值到缓存行中。 - 15 CPU 0 收到 Read 消息,它将包含
b最新值的缓存行发送给 CPU 1,然后将其标记为 “shared” 状态。 - 16 CPU 1 收到
b缓存行的数据,然后将它更新到缓存行。 - 17 CPU 1 现在可以拿到
b的新值 1,所以它退出while循环,继续往下执行。 - 18 CPU 1 执行
assert(a == 1),但是发现a不在缓存行中(第8步已经移除)。一旦它从 CPU 0 读到a缓存行的值,它可以拿到a的最新值,然后断言就成功了。
正如你所看到的,流程很简单,只是 “加载 a 值“变得复杂了一些。
Store Sequences Result in Unnecessary Stalls
标题可能翻译不准,保留英文原文,含义是“不停顿地保存一些列结果”。
不幸的是,每个 store buffer 都相当的小,意味着一个CPU一定数量的存 store buffer 的操作后,store buffer 很快会被填满(比如,一直发生 cache miss)。每当 store buffer 耗尽,CPU 就再一次等待 invalidation 完成才能执行后续的操作。相同的情形可能出现在内存屏障,当所有后续 store 指令必须等待 invalidation 完成,不管是否 store 结果是缓存失效。
这种情况可以通过提高 Invalidate Acknowledge 消息达到速度来解决。方法是每个CPU使用 invalidate 消息队列。
Invalidate 队列
Invalidate Acknowledge 消息需要花很长时间的一个原因是相应的缓存行由于 cache 繁忙导致清除时间延迟。比如,一个 CPU 频繁的加载和存储数据,所有的数据也都在缓存行中。另外,如果有大量的 Invalidate 消息周期性的到达,CPU 会暂停指令执行,转而执行 Invalidate 操作,这会暂停其他所有的 CPU。
然而,CPU 在发送 Acknowledge 前并不需要真的清空缓存行,它会将 Invalidate 消息放入队列,在发送关于这个缓存行的任何消息前,CPU 会处理这个 Invalidate 消息。
Invalidate 队列和 Invalidate Acknowledge
图-8显示一个带 Invalidate 消息队列的缓存系统。一个带有 Invalidate 队列的 CPU 可以在 invalidate 放入队列就立刻的回复 invalidate 的确认消息,这样就不需要等到相应的缓存行都真的执行了 invalidate 操作。当然,CPU 准备发送 Invalidate 消息时需要检查 invalidate 消息队列:如果相应缓存行的条目存在 invalidate 队列时,CPU 不能立刻发送 invalidte 消息,它必须等到这个 invalidate 队列的条目被执行。
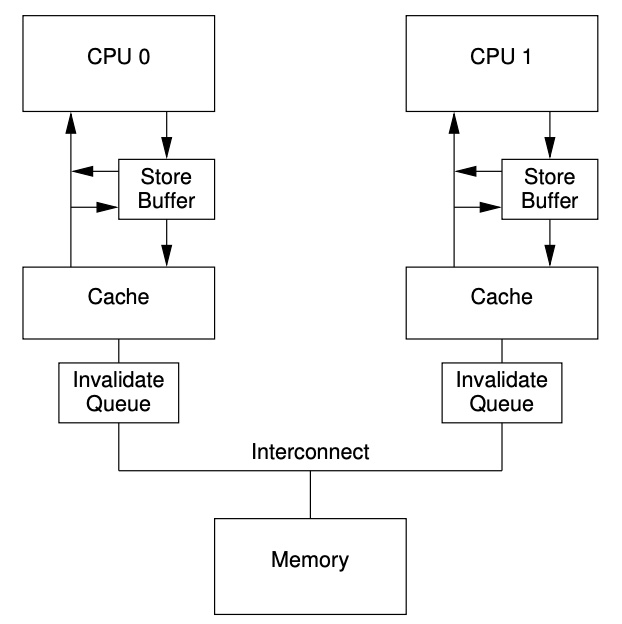
图-8 带有 lnvalidate 消息队列缓存系统
CPU承诺在发送任何关于缓存行的MESI协议消息前,都会将这个缓存行的 invalidate 队列的消息取出并执行。只要相应的消息结果竞争不大,CPU的承诺也不费劲。
然而,事实上,invalidate 消息在 invalidate 消息队列时可以被缓存的,这样就会造成内存无序的情况,下文分析。
Invalidate 队列和内存屏障
我们假设 CPU 将 invalidate 请求加入队列,然后直接回复 invalidate acknowledge 消息。这种方法可以最小化缓存 invalidation (清除)的延迟,正如 CPU 的 store buffer 那样,但是欺骗了内存屏障。请看下面的例子。
假设 a 和 b 的值初始化为0,a 的缓存行有多个副本,也就是 “shared” 状态,b 存储在 CPU 0,状态是 “exclusive” 或者 “modified” 状态。然后 当 CPU 1 执行bar() 时,CPU 0 执行 foo() ,代码如下:
1 | void foo(void) |
操作序列如下:
- 1 CPU 0 执行
a = 1。相应的缓存行在 CPU 0的缓存中是只读,所以 CPU 0 将a的新值存到 store buffer,然后发起 Invalidate 消息要让 CPU 1中a缓存行的数据清除。 - 2 CPU 1 执行
while(b == 0) continue;,但是b不在缓存行中,因此发起一个 Read 消息。 - 3 CPU 1 收到 CPU 0 的 Invalidate 消息,直接将这个消息加入到 invalidate 队列,立刻回复 Invalidate Acknowledge 消息。
- 4 CPU 0 收到 CPU 1 的回复,因此可以自由的执行完
smp_mb(),然后将a的值从 store buffer 取出应用到缓存行。 - 5 CPU 0 执行
b = 1,该 CPU 已经拥有它的缓存行(换言之,缓存行的状态可能是 “exclusive” 或者是 “modified” 状态),所以它将新值存储到缓存行中。 - 6 CPU 0 收到 Read 消息,将
b的缓存行最新值发送给 CPU 1,并且标记b缓存行的状态是 “shared”。 - 7 CPU 1 收到
b缓存行的数据,然后将它保存到缓存行。 - 8 CPU 1 现在可以完成
while(b == 0) continue,因为它发现b的值是 1,继续执行下面的语句。 - 9 CPU 1 执行
assert(a == 1),因为a的旧值依然存在 CPU 1 的缓存行中,断言失败。 - 10 不顾断言失败,CPU 1 执行 invalidate 队列的消息,标记
a的缓存行失效。
很明显加速了 invalidation 回复后造成内存屏障失效了。然后,内存屏障指令也可以使用在 invalidate 队列,所以,当一个 CPU 执行一个内存屏障后,它标记所有当前 invalidate 队列的条目,然后强制接下来的 load 操作等待,直到所有的被标记的条目都已经应用到缓存行。因此我们可以在 bar() 加一个内存屏障,代码如下。
1 | void foo(void) |
修改后,操作序列如下:
- 1 CPU 0 执行
a = 1。相应的缓存行在 CPU 0的缓存中是只读,所以 CPU 0 将a的新值存到 store buffer,然后发起 Invalidate 消息要让 CPU 1中a缓存行的数据清除。 - 2 CPU 1 执行
while(b == 0) continue;,但是b不在缓存行中,因此发起一个 Read 消息。 - 3 CPU 1 收到 CPU 0 的 Invalidate 消息,直接将这个消息加入到 invalidate 队列,立刻回复 Invalidate Acknowledge 消息。
- 4 CPU 0 收到 CPU 1 的回复,因此可以自由的执行完
smp_mb(),然后将a的值从 store buffer 取出应用到缓存行。 - 5 CPU 0 执行
b = 1,该 CPU 已经拥有它的缓存行(换言之,缓存行的状态可能是 “exclusive” 或者是 “modified” 状态),所以它将新值存储到缓存行中。 - 6 CPU 0 收到 Read 消息,将
b的缓存行最新值发送给 CPU 1,并且标记b缓存行的状态是 “shared”。 - 7 CPU 1 收到
b缓存行的数据,然后将它保存到缓存行。 - 8 CPU 1 现在可以完成
while(b == 0) continue,因为它发现b的值是 1,继续执行下面的语句。 - 9 到了
smp_mb(),CPU 1 必须暂停直到所有之前的 invalidate 队列的消息都执行完成。 - 10 CPU 1 现在执行 invalidate 消息,将
a缓存行清除。 - 11 CPU 1 执行
assert(a == 1),由于a的缓存行之前被清除,已经不在 CPU 1 的缓存中,需要发起 Read 消息。 - 12 CPU 0 回复 Read 消息,消息包含
a缓存行的数据。 - 13 CPU 1 收到
a缓存行的数据,值为 1,所以断言成功。
通过很多 MESI 消息传输,CPU 能正确执行得到正确的结果。这一部分展示了为什么 CPU 设计者会十分关心他们的缓存一致性优化。
读写内存屏障
前面的章节说到,内存屏障用来标记 store buffer 和 invalidate 队列的条目。但是在我们给的示例代码中,foo() 没有理由对 invalidate 队列做任何事,bar() 也没有理由对 store buffer 做任何事。
很多的 CPU 架构因此提供较弱的内存屏障指令,这些指令处理 invalidate 或者 store buffer 其中的一个,又或者两个多处理。粗略的说,“读内存屏障”仅标记 invalidate 队列,“写内存屏障”仅标记 store buffer,完整功能内存屏障指令两个都标记。
读内存屏障的效果是仅对 CPU 的 load 操作(或者读操作)排序,如此一来,所有在读内存屏障前的 load 操作都必须先完成才能执行读内存屏障之后的 load 操作。同样的,写内存屏障的效果是仅对 CPU 的 store 操作(或者写操作)排序,如此一来,所有在写内存屏障之前的 store 操作比先完成才能执行写内存屏障之后的 store 操作。完整功能内存屏障指令对 load 和 store 都排序。
如果我们更新 foo 和 bar 为使用读写内存屏障,代码如下:
1 | void foo(void) |
一个计算机系统的内存屏障更加复杂,但是通常来说,理解这3个变种就可以很好的介绍内存屏障了。
内存屏障的顺序
这一节我们将呈现一些非常巧妙的内存屏障使用例子。有些使用技巧是通用的,而有些技巧在特定的CPU架构才有效,如果你的目标是设计通用的代码,就不要考虑特定CPU才支持的技巧。为了让我们更好的理解技巧,我们首先关注对违反顺序规则的架构(ordering-hostile architecture)。
Ordering-Hostile Architecture
Ordering-Hostile 架构的计算机系统已经出现十年多,但是每种硬件系统对顺序的处理都有细微差别,要理解他们需要详细的了解具体的硬件架构。不应该让用户着迷特定硬件产生的技术规范,应该要设计比较通用的内存 Ordering-Hostile 系统架构。
我们设计的这套硬件支持如下排序规则:
- 每个CPU都按照程序顺序规则访问内存。
- CPU 会对带有 store 操作的指令重排序,仅且仅当两个操作引用了不同地址。
- 一个CPU的读内存屏障之前的 load 指令,能被其他CPU在执行这个读内存屏障后面的 load 指令之前感知到。这里说的是内存可见性,执行读内存屏障后面的 load 指令可定能看到执行此读内存屏障之前的 load 指令的内容。(书上原文是 All of a given CPU’s loads preceding a read memory barrier (smp_rmb()) will be perceived by all CPUs to precede any loads following that read memory barrier)。
- 一个CPU的写内存屏障之前的 store 指令,能被其他CPU在执行这个写内存屏障后面的 store 指令之前感知到。(书上原文是 All of a given CPU’s stores preceding a write memory barrier (smp_wmb()) will be perceived by all CPUs to precede any stores following that write memory barrier.)。
- 一个CPU的内存屏障之前的访问指令,能被其他CPU在执行这个写内存屏障后面的 访问指令之前感知到。
想象一个大的 NUCA 系统(non-uniform cache architecture),为了给每个互联的 Node 节点提供公平的分配策略,每个 CPU 要一个队列,如图-9所示。尽管一个CPU在内存屏障下会按照顺序执行,但是在一组 Node 节点下的两个 CPU 依然会乱序执行。
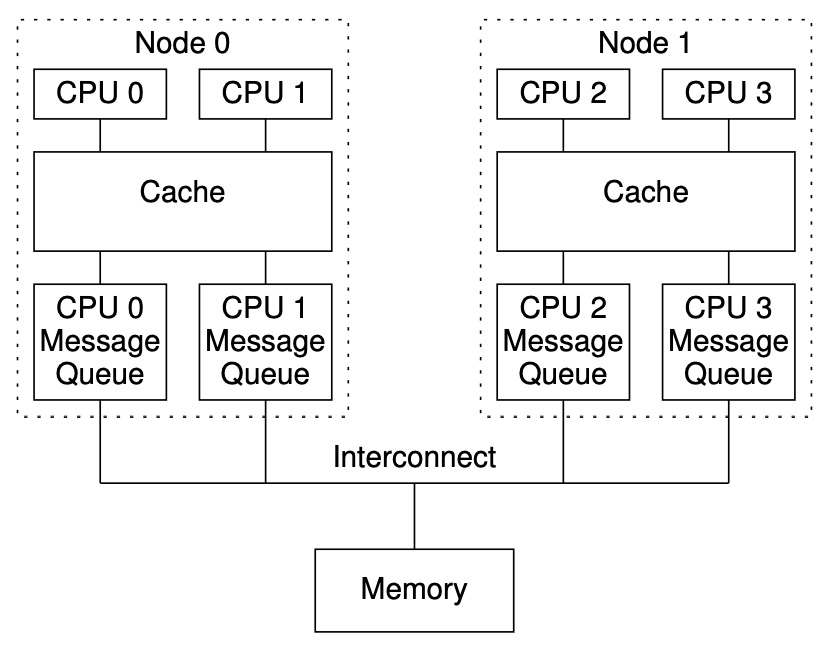
图-9 一种 Ordering-Hostile Architecture
下面来说说乱序的原因。
例1
图-10 是 3 个 CPU 并发执行三段代码的示意图。 a,b,c都初始化为0。
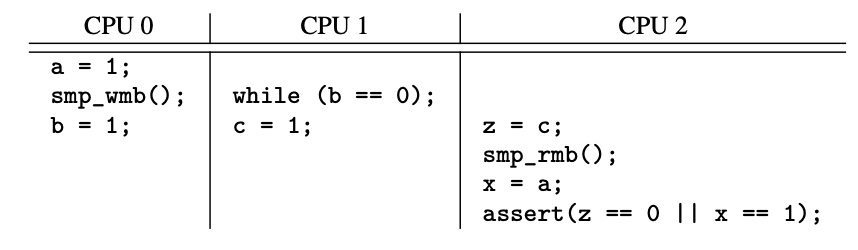
图-10 代码示例1
假如CPU 0最近经历了大量的缓存失效,以致它的 message queue 是满的;而 CPU 1 一直处于独占缓存的情况下运行,以致它的 message queue 是空的。CPU 0 赋值给 a 和 b 将会立刻出现在 Node 0 的缓存(对 CPU 1 也是可见的),但是随后会被 CPU 0 之前缓存失效的大量动作所阻塞。相应的,CPU 1 赋值给 c 时会经历 CPU 1 之前的空 message queue,因此 CPU 2 可能看到 CPU 1 对 c 的赋值,而 CPU 0 对 a 的赋值此时 CPU 1 还看不到。最终导致断言失败。
例2
图-11 是 3个CPU并发执行三段代码的示意图。 a,b 都初始化为0。

图-11 代码示例2
假如CPU 0最近经历了大量的缓存失效,以致它的 message queue 是满的;而 CPU 1 一直处于独占缓存的情况下运行,以致它的 message queue 是空的。CPU 0 赋值给 a 将会立刻出现在 Node 0 的缓存(对 CPU 1 也是可见的),但是随后会被 CPU 0 之前缓存失效的大量动作所阻塞。CPU 1的对 b 赋值经历 CPU 1 之前的空 message queue。因此 CPU 2 可能会看到 CPU 1 对 b 的赋值,但是此时还看不到 CPU 0 对 a 的赋值。最终导致断言失败。
例3
图-13 是 3个CPU并发执行三段代码的示意图。 所有变量都初始化为0。

图-12 代码示例3
注意,不管是 CPU 1 还是 CPU 2,都需要先看到 CPU 0 在第3行对 b 的赋值才能执行到第5行。一旦CPU 1 和CPU 2 执行到第4行的内存屏障,他们就都能够看到 CPU 0 在第2行内存屏障之前的所有赋值,当然就包括 a。同样的,CPU 0 在执行第9行的 e 赋值之前,也会一直等待 CPU 1 和 CPU 2 对 c 和 d 的赋值能够被自己看到,当 CPU 0 能指定到第8行时也说明 CPU 0 的对 b 的赋值已经被 CPU 1 和 CPU 2 可见。最后CPU 2断言会成功,因为它已经能看到 a 的值。
Linux 内核的 synchronize_rcu() 原语使用的就是此例类似的算法。